超详细robots.txt大全和禁止目录收录及指定页面
时间:2017-12-19
robots.txt写法大全和robots.txt语法的作用
1如果允许所有搜索引擎访问网站的所有部分的话 我们可以建立一个空白的文本文档,命名为robots.txt放在网站的根目录下即可。
robots.txt写法如下:
User-agent: *
Disallow:
或者
User-agent: *
Allow: /
2如果我们禁止所有搜索引擎访问网站的所有部分的话
robots.txt写法如下:
User-agent: *
Disallow: /
3如果我们需要某一个搜索引擎的抓取的话,比如百度,禁止百度索引我们的网站的话
robots.txt写法如下:
User-agent: Baiduspider
Disallow: /
4如果我们禁止Google索引我们的网站的话,其实跟示例3一样,就是User-agent:头文件的蜘蛛名字改成谷歌的Googlebot
即可
robots.txt写法如下:
User-agent: Googlebot
Disallow: /
5如果我们禁止除Google外的一切搜索引擎索引我们的网站话
robots.txt写法如下:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /
6如果我们禁止除百度外的一切搜索引擎索引我们的网站的话
robots.txt写法如下:
User-agent: Baiduspider
Disallow:
User-agent: *
Disallow: /
7如果我们需要禁止蜘蛛访问某个目录,比如禁止admin、css、images等目录被索引的话
robots.txt写法如下:
User-agent: *
Disallow: /css/
Disallow: /admin/
Disallow: /images/
8如果我们允许蜘蛛访问我们网站的某个目录中的某些特定网址的话
robots.txt写法如下:
User-agent: *
Allow: /css/my
Allow: /admin/html
Allow: /images/index
Disallow: /css/
Disallow: /admin/
Disallow: /images/
9我们看某些网站的robots.txt里的Disallow或者Allow里会看很多的符号,比如问号星号什么的,如果使用“*”,主要是限制访问某个后缀的域名,禁止访问/html/目录下的所有以”.htm”为后缀的URL(包含子目录)。
robots.txt写法如下:
User-agent: *
Disallow: /html/*.htm
10如果我们使用“$”的话是仅允许访问某目录下某个后缀的文件
robots.txt写法如下:
User-agent: *
Allow: .asp$
Disallow: /
11如果我们禁止索引网站中所有的动态页面(这里限制的是有“?”的域名,例如index.asp?id=1)
robots.txt写法如下:
User-agent: *
Disallow: /*?*
有些时候,我们为了节省服务器资源,需要禁止各类搜索引擎来索引我们网站上的图片,这里的办法除了使用“Disallow: /images/”这样的直接屏蔽文件夹的方式之外,还可以采取直接屏蔽图片后缀名的方式。
示例12
如果我们禁止Google搜索引擎抓取我们网站上的所有图片(如果你的网站使用其他后缀的图片名称,在这里也可以直接添加)
robots.txt写法如下:
User-agent: Googlebot
Disallow: .jpg$
Disallow: .jpeg$
Disallow: .gif$
Disallow: .png$
Disallow: .bmp$
13如果我们禁止百度搜索引擎抓取我们网站上的所有图片的话
robots.txt写法如下:
User-agent: Baiduspider
Disallow: .jpg$
Disallow: .jpeg$
Disallow: .gif$
Disallow: .png$
Disallow: .bmp$
14除了百度之外和Google之外,禁止其他搜索引擎抓取你网站的图片
(注意,在这里为了让各位看的更明白,因此使用一个比较笨的办法——对于单个搜索引擎单独定义。)
robots.txt写法如下:
User-agent: Baiduspider
Allow: .jpeg$
Allow: .gif$
Allow: .png$
Allow: .bmp$
User-agent: Googlebot
Allow: .jpeg$
Allow: .gif$
Allow: .png$
Allow: .bmp$
User-agent: *
Disallow: .jpg$
Disallow: .jpeg$
Disallow: .gif$
Disallow: .png$
Disallow: .bmp$
15仅仅允许百度抓取网站上的“JPG”格式文件
(其他搜索引擎的办法也和这个一样,只是修改一下搜索引擎的蜘蛛名称即可)
robots.txt写法如下:
User-agent: Baiduspider
Allow: .jpg$
Disallow: .jpeg$
Disallow: .gif$
Disallow: .png$
Disallow: .bmp$
16仅仅禁止百度抓取网站上的“JPG”格式文件
robots.txt写法如下:
User-agent: Baiduspider
Disallow: .jpg$
17如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。但是,以 ? 结尾的网址可能是您要包含的网页版本。在此情况下,沃恩可将与 Allow 指令配合使用。
robots.txt写法如下:
User-agent:*
Allow:/*?$
Disallow:/*?
Disallow:/ *?
一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。
18如果我们想禁止搜索引擎对一些目录或者某些URL访问的话,可以截取部分的名字
robots.txt写法如下:
User-agent:*
Disallow: /plus/feedback.php?
以上内容供大家参考下即可。
相关文章
 说说Robots.txt限制收录与Google网站管理员工具最近有朋友询问:用谷歌site你的站发现google没收录你的tag页,我的怎么?有还大部分是 ?倡萌认为,很多新手估计都不明其中的道理,加上自己想说说 倡萌的自留
说说Robots.txt限制收录与Google网站管理员工具最近有朋友询问:用谷歌site你的站发现google没收录你的tag页,我的怎么?有还大部分是 ?倡萌认为,很多新手估计都不明其中的道理,加上自己想说说 倡萌的自留 Robots.txt 是什么/有什么用/怎么写1. Robots.txt是什么? 我们都知道txt后缀的文件是纯文本文档,robots是机器人的意思,所以顾名思义,robots.txt文件也就是给搜索引擎蜘蛛这个机器人看的纯文本
Robots.txt 是什么/有什么用/怎么写1. Robots.txt是什么? 我们都知道txt后缀的文件是纯文本文档,robots是机器人的意思,所以顾名思义,robots.txt文件也就是给搜索引擎蜘蛛这个机器人看的纯文本- robots.txt是什么robots.txt基本介绍 robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。 当一个
 百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没被QQ和微信
百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没被QQ和微信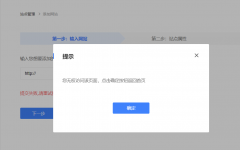 百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜了一下,也
百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜了一下,也