Robots.txt 是什么/有什么用/怎么写
时间:2016-04-131. Robots.txt是什么?
我们都知道txt后缀的文件是纯文本文档,robots是机器人的意思,所以顾名思义,robots.txt文件也就是给搜索引擎蜘蛛这个机器人看的纯文本文件。robots.txt是搜索引擎公认遵循的一个规范文档,它告诉Google、百度等搜索引擎哪些网页允许抓取、索引并在搜索结果中显示,哪些网页是被禁止收录的。 搜索引擎蜘蛛spider(Googlebot/Baiduspider)来访问你的网站页面的时候,首先会查看你的网站根目录下是否有robots.txt文件,如果有则按照里面设置的规则权限对你网站页面进行抓取和索引。
如淘宝网就通过设置robots.txt屏蔽百度搜索引擎:
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
2. robots.txt有什么作用?
robots.txt文件至少有下面两方面的作用:
通过设置屏蔽搜索引擎访问不必要被收录的网站页面,可以大大减少因spider抓取页面所占用的网站带宽,小网站不明显,大型网站就很明显了。
设置robots.txt可以指定google或百度不去索引哪些网址,比如我们通过url重写将动态网址静态化为永久固定链接之后,就可以通过robots.txt设置权限,阻止Google或百度等搜索引擎索引那些动态网址,从而大大减少了网站重复页面,对SEO优化起到了很明显的作用。
3. robots.txt 怎么写?
关于如何写robots.txt文件,在下面我们会以WordPress博客来作更具体举例说明。这里先提示几点robots.txt写法中应该注意的地方。如robots.txt文件里写入以下代码:
User-agent: *
Disallow:
Allow: /
robots.txt必须上传到你的网站根名录下,在子目录下无效;
robots.txt,Disallow等必须注意大小写,不能变化;
User-agent,Disallow等后面的冒号必须是英文状态下的,冒号后面可以空一格,也可以不空格。网上有人说冒号后面必须有空格,其实没有也是可以的。
请看谷歌中文网站管理员博客的设置就是这样:http://www.googlechinawebmaster.com/robots.txt ;
User-agent表示搜索引擎spider:星号“*”代表所有spider,Google的spider是“Googlebot”,百度是“Baiduspider”;
Disallow:表示不允许搜索引擎访问和索引的目录;
Allow:指明允许spider访问和索引的目录,Allow: / 表示允许所有,和Disallow: 等效。
4. 特殊案例情况:robots.txt与子目录绑定的问题
如果forum用的是绑定子目录的方式,而实际使用的是比如是forum.hcm602.cn这样的二级域名,那么就要避免 www.cmhello.com/forum/这样的url被搜索引擎收录,可以在主目录中的robots.txt中加入:
User-agent: *
Disallow: /forum/
Robots.txt 文件必须放在网站的根目录。放在子目录的 Robots.txt 文件搜索引擎不能爬取到,所以不会起任何作用。(除非你的子目录是一个绑定了域名的新网站)
本文来自网络,跟版模板网(www.cmhello.com) 整理编辑,请原创作者及时与跟版模板网联系。
相关文章
 超详细robots.txt大全和禁止目录收录及指定页面robots.txt写法大全和robots.txt语法的作用 1如果允许所有搜索引擎访问网站的所有部分的话 我们可以建立一个空白的文本文档,命名为robots.txt放在网站的根目录
超详细robots.txt大全和禁止目录收录及指定页面robots.txt写法大全和robots.txt语法的作用 1如果允许所有搜索引擎访问网站的所有部分的话 我们可以建立一个空白的文本文档,命名为robots.txt放在网站的根目录 说说Robots.txt限制收录与Google网站管理员工具最近有朋友询问:用谷歌site你的站发现google没收录你的tag页,我的怎么?有还大部分是 ?倡萌认为,很多新手估计都不明其中的道理,加上自己想说说 倡萌的自留
说说Robots.txt限制收录与Google网站管理员工具最近有朋友询问:用谷歌site你的站发现google没收录你的tag页,我的怎么?有还大部分是 ?倡萌认为,很多新手估计都不明其中的道理,加上自己想说说 倡萌的自留- 主流搜索引擎网站登录入口及注意事项当你搭建了一个新的网站时,你必须要做一件事就是提交网站到各大搜索引擎,下面是倡萌推荐的一些主要的搜索引擎登录入口。 提交网站到搜索引擎应该注意的几点:
- robots.txt是什么robots.txt基本介绍 robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。 当一个
 百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没被QQ和微信
百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没被QQ和微信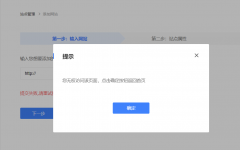 百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜了一下,也
百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜了一下,也