删除 sed 或类似中的 html 标签
时间:2023-07-31问题描述
我正在尝试从网页中获取表格内容.我只需要内容,但不需要标签 <tr></tr>.我什至不需要tr"或td"只是内容.例如:
I am trying to fetch contents of table from a wepage. I jsut need the contents but not the tags <tr></tr>. I don't even need "tr" or "td" just the content. for eg:
<td> I want only this </td>
<tr> and also this </tr>
<TABLE> only texts/numbers in between tags and not the tags. </TABLE>
我也想把这样的第一列输出放在一个新的 csv 文件中列 1,信息 1,信息 2,信息 3coumn2,info1,info2,info3
also I would like to put the first column output like this in a new csv file column1,info1,info2,info3 coumn2,info1,info2,info3
我尝试 sed 删除模式 <tr> <td> 但是当我获取表格时还有其他标签,例如 <color> <span> 等所以我想要的是删除所有标签;简而言之,所有带有 <和 > .
I tried sed to deleted patters <tr> <td> but when I fetch table there are also other tags like <color> <span> etc. so I want is to delete all the tags; in short everything with < and > .
推荐答案
sed 's/<[^>]+>//g' 会去掉所有标签,但是您可能想用空格替换它们,这样彼此相邻的标签就不会一起运行: <td>one</td><td>two</td> 变为:onetwo.所以你可以做 sed 's/<[^>]+>//g' 所以它会输出 one two (好吧,实际上是 一二).
sed 's/<[^>]+>//g' will strip all tags out, but you might want to replace them with a space so tags that are next to each other don't run together: <td>one</td><td>two</td> becoming: onetwo. So you could do sed 's/<[^>]+>/ /g' so it would output one two (well, actually one two).
也就是说,除非您只需要原始文本,而且听起来您正试图在剥离标签后对数据进行一些转换,否则像 Perl 这样的脚本语言可能是更合适的工具来完成这些工作.
That said unless you need just the raw text, and it sounds like you are trying to do some transformations to the data after stripping the tags, a scripting language like Perl might be a more fitting tool to do this stuff with.
由于 mu 太短了,提到抓取 HTML 可能有点冒险,使用真正为您解析 HTML 的东西将是最好的方法.PHPs DOM API 非常适合这类事情.
As mu is too short mentioned scraping HTML can be a bit dicey, using something that actually parses the HTML for you would be the best way to do this. PHPs DOM API is pretty good for these kinds of things.
这篇关于删除 sed 或类似中的 html 标签的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持跟版网!
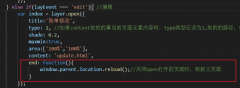 layer.open打开的页面关闭时,父页面刷新的方法layer.open打开的页面关闭时,父页面刷新的方法,在layer.open中添加: end: function(){ window.parent.location.reload();//关闭open打开的页面时,刷新父页面 }
layer.open打开的页面关闭时,父页面刷新的方法layer.open打开的页面关闭时,父页面刷新的方法,在layer.open中添加: end: function(){ window.parent.location.reload();//关闭open打开的页面时,刷新父页面 }