Consistent Hashing的简单说明
时间:2016-04-05Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。

图4 Consistent Hashing:基本原理
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。

图5 Consistent Hashing:添加服务器
因此,Consistent Hashing最大限度地抑制了键的重新分布。而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
(1 - n/(n+m)) * 100
相关文章
 Nginx使用中文文件名中文目录404错误的解决办法一:确定你的系统是UTF编码 [root@Tserver ~]# env|grep LANG LANG=en_US.UTF-8 二:NGINX配置文件里默认编码设置为utf-8 server { listen 80; server_name .ing
Nginx使用中文文件名中文目录404错误的解决办法一:确定你的系统是UTF编码 [root@Tserver ~]# env|grep LANG LANG=en_US.UTF-8 二:NGINX配置文件里默认编码设置为utf-8 server { listen 80; server_name .ing 网站无法加载woff字体文件的解决办法?有客户反馈在安装网站后,woff、woff2字体无法加载,导致无法显示图标文件,这种情况要怎么解决呢? 这是因为服务器IIS默认是没有SVG,WOFF,WOFF2这几个文件类型
网站无法加载woff字体文件的解决办法?有客户反馈在安装网站后,woff、woff2字体无法加载,导致无法显示图标文件,这种情况要怎么解决呢? 这是因为服务器IIS默认是没有SVG,WOFF,WOFF2这几个文件类型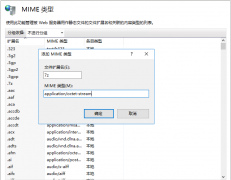 网站服务器不支持.7z文件下载的解决方法7-Zip是一款号称有着现今最高压缩比的压缩软件,它不仅支持独有的7z文件格式,而且还支持各种其它压缩文件格式,其中包括ZIP, RAR, CAB, GZIP, BZIP2和TAR。此软
网站服务器不支持.7z文件下载的解决方法7-Zip是一款号称有着现今最高压缩比的压缩软件,它不仅支持独有的7z文件格式,而且还支持各种其它压缩文件格式,其中包括ZIP, RAR, CAB, GZIP, BZIP2和TAR。此软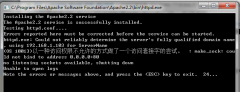 安装 Apache 出现
安装 Apache 出现 以一种访问权限不允许的方式做了一个访问套接字的尝试 安装 Apache 出现 OS 10013 以一种访问权限不允许的方式做了一个访问套接字的尝试 如下截图: 提示: make_sock: could not bind to address 0.0.0.0:80 这个问- nginx加载伪静态文件.htaccess的办法很多网站需要采用伪静态来访问动态网页。所以像phpcms这样的系统,都提供了一个.htaccess文件,供写伪静态规则。但这个规则是针对Apache的。在nginx服务器上并不
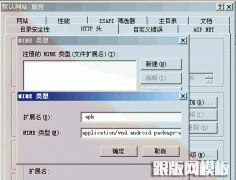 怎么让服务器iis6-7支持.apk文件下载随着智能手机的普及,越来越多的人使用手机上网,很多网站也应手机上网的需要推出了网站客户端,.apk文件就是安卓(Android)的应用程序后缀名,默认情况下,使用I
怎么让服务器iis6-7支持.apk文件下载随着智能手机的普及,越来越多的人使用手机上网,很多网站也应手机上网的需要推出了网站客户端,.apk文件就是安卓(Android)的应用程序后缀名,默认情况下,使用I