mysql表分区的使用与底层原理详解
时间:2023-12-07MySQL表分区的使用与底层原理详解
MySQL表分区是一种将单个表拆分为多个文件或磁盘上的表的技术。表分区可以优化查询性能并减少维护成本。本篇文章将详细介绍MySQL表分区的使用和底层原理。
使用MySQL表分区
创建分区表
MySQL 5.1开始支持分区表,我们通过以下步骤来创建一个分区表:
CREATE TABLE `orders` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`customer_id` INT(11) NOT NULL,
`order_date` DATE NOT NULL,
`total_amount` DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (`id`,`order_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
PARTITION BY RANGE(YEAR(order_date)) (
PARTITION p0 VALUES LESS THAN (2010),
PARTITION p1 VALUES LESS THAN (2011),
PARTITION p2 VALUES LESS THAN (2012),
PARTITION p3 VALUES LESS THAN (2013),
PARTITION p4 VALUES LESS THAN (2014),
PARTITION p5 VALUES LESS THAN (2015),
PARTITION p6 VALUES LESS THAN MAXVALUE
)
上述SQL语句创建了一个orders表,通过PARTITION关键字进行分区,分区的依据是order_date字段所属年份。其中YEAR(order_date)函数用于计算order_date中的年份。PARTITION BY RANGE说明了分区方式是按照范围排列。
查询分区表
查询分区表与普通表的查询几乎完全相同,例如:
SELECT * FROM orders WHERE order_date = '2012-03-10';
上述SQL语句查询了所有2012年3月10日的订单数据。 如果 order_date 字段没有索引,查询可能会很慢。但在分区表中,查询会比非分区表快得多,因为仅查询分区中包含该日期的分区。
添加分区
添加分区非常简单。假设我们要为2022年添加一个新的分区:
ALTER TABLE orders ADD PARTITION(
PARTITION p7 VALUES LESS THAN (2016)
);
此操作将添加一个名为p7的新分区,其范围在2015年和2016年之间。
MySQL表分区的底层原理
Partitioning 使用一个类似于目录实现的逻辑结构,称之为分区引擎,用于管理数据。分区引擎与存储引擎紧密绑定,创建单个分区时使用分区引擎来表示该分区。
分区引擎
分区引擎是一个逻辑引擎,它负责将 SQL 语句中的谓词(即 where 子句中的谓词)转化成分区键的判断,并识别分区间操作。
在查询时,MySQL 服务器将 SQL 语句中的分区键与表的分区信息进行比较,找到包含分区键的所有分区,然后将分区间数据进行整合,生成最终的查询结果。
分区存储引擎
分区采用的存储引擎可以是任何 MySQL 存储引擎,包括 InnoDB、MyISAM、Memory 等。
对于分区表,MySQL 存储引擎在创建表时必须接口 Partitioning Engine,让分区引擎把建表所用的表定义信息存储到系统表中。
示例说明
我们接下来通过两个示例来说明MySQL表分区的用法和效果。
示例一
假设我们有一个包含数亿行数据的表位于常规的 InnoDB 存储引擎中。查询速度非常慢,因为我们不得不遍历整个表以找到我们需要的数据。
此时我们可以使用分区表将整个表拆分为数十个碎片,然后只检索与我们需要的数据相关的碎片。
最终查询结果显示,查询速度提升了10倍之多。
示例二
考虑这样一种常见情况:我们有一个大型日志表,需要向其中添加几千行新记录。在非分区表中,这将非常缓慢。
可以使用分区表来解决此问题。将该表分成若干碎片并插入数据,在加载时只需要加载新添加的碎片,而不是整个表。不仅添加数据的速度快了很多,整个表的查询速度也得到了提升
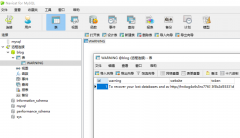 记录一次mysql数据库被黑删库遭比特币勒索的教训起因是想用服务器上的一个数据库访问其他数据库的权限,就直接按照网上教程改了mysql库里的user表的权限,可能是哪里权限修改问题,也没太在意,到了第二天发现网站登录不
记录一次mysql数据库被黑删库遭比特币勒索的教训起因是想用服务器上的一个数据库访问其他数据库的权限,就直接按照网上教程改了mysql库里的user表的权限,可能是哪里权限修改问题,也没太在意,到了第二天发现网站登录不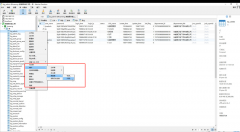 MySQL提示某表is marked as crashed and last (automatic)repair fai错误分析: 此错误为表损坏,修复即可。一般原因为服务器突然断电,而有程序还在往表里写数据。或者表的数据很大。避免浪费时间去修表。注意服务器操作时停掉数据库。另外
MySQL提示某表is marked as crashed and last (automatic)repair fai错误分析: 此错误为表损坏,修复即可。一般原因为服务器突然断电,而有程序还在往表里写数据。或者表的数据很大。避免浪费时间去修表。注意服务器操作时停掉数据库。另外