MongoDB学习笔记(六) MongoDB索引用法和效率分析
时间:2016-09-25MongoDB中的索引其实类似于关系型数据库,都是为了提高查询和排序的效率的,并且实现原理也基本一致。由于集合中的键(字段)可以是普通数据类型,也可以是子文档。MongoDB可以在各种类型的键上创建索引。下面分别讲解各种类型的索引的创建,查询,以及索引的维护等。
一、创建索引
1. 默认索引
MongoDB有个默认的“_id”的键,他相当于“主键”的角色。集合创建后系统会自动创建一个索引在“_id”键上,它是默认索引,索引名叫“_id_”,是无法被删除的。我们可以通过以下方式查看:
var _idIndex = mongoCollection.Metadata.Indexes.Single(x => x.Key == "_id_");
Console.WriteLine(_idIndex);
2. 单列索引
在单个键上创建的索引就是单列索引,例如我们要在“UserInfo”集合上给“UserName”键创建一个单列索引,语法如下:(1表示正序,-1逆序)
接着,我们用同样方法查找名为“_UserName_”的索引
var _UserName_Index = mongoCollection.Metadata.Indexes.Single(x => x.Key == "_UserName_");
Console.WriteLine(_UserName_Index);
3.组合索引
另外,我们还可以同时对多个键创建组合索引。如下代码创建了按照“UserId”正序,“UserName”逆序的组合索引:
4.子文档索引
我们可以对文档类型的键创建各种索引,例如单列索引,如下创建用户详细信息“Detail”的单列索引:
对子文档的键创建组合索引:例如在“Detail.Address”和“Detail.Age”上创建组合索引:
5.唯一索引
唯一索引限制了对当前键添加值时,不能添加重复的信息。值得注意的是,当文档不存在指定键时,会被认为键值是“null”,所以“null”也会被认为是重复的,所以一般被作为唯一索引的键,最好都要有键值对。
对“UserId”创建唯一索引(这时候最后一个参数为“true”):
二、维护索引
1. 查询索引
通过索引名查询的方式已有介绍。但有时候,我们可能忘记了索引名,怎么查询呢?
下面提供一个遍历全部索引的方法,打印全部索引信息:
foreach (var index in mongoCollection.Metadata.Indexes)
{
Console.WriteLine(index.Value);
}
输出结果示例:
{ "name": "_id_", "ns": "myDatabase.UserInfo", "key": { "_id": 1 } }
{ "name": "_UserId_unique_", "ns": "myDatabase.UserInfo", "key": { "UserId": 1 }, "unique": true, "_id": "4d8f406ab8a4730b78000005" }
{ "name": "_UserName_", "ns": "myDatabase.UserInfo", "key": { "UserName": 1 }, "unique": false, "_id": "4d8f406ab8a4730b78000006" }
{ "name": "_Detail.Address_Detail.Age_", "ns": "myDatabase.UserInfo", "key": { "Detail.Address": 1, "Detail.Age": -1 }, "unique": false, "_id": "4d8f406ab8a4730b78000007" }
{ "name": "_UserId_UserName_", "ns": "myDatabase.UserInfo", "key": { "UserId": 1, "UserName": -1 }, "unique": false, "_id": "4d8f406ab8a4730b78000008" }
{ "name": "_Detail_", "ns": "myDatabase.UserInfo", "key": { "Detail": 1 }, "unique": false, "_id": "4d8f406ab8a4730b78000009" }
可见,集合的索引也是通过一个集合来维护的。name表示索引名,ns表示索引属于哪个库哪个集合,key表示索引在哪个键上,正序还是逆序,unique表示是否为唯一索引,等等...
2. 删除索引
新手常陷入的误区是,认为集合被删除,索引就不存在了。关系型数据库中,表被删除了,索引也不会存在。在MongoDB中不存在删除集合的说法,就算集合数据清空,索引都是还在的,要移除索引还需要手工删除。
例如,删除名为“_UserName_”的索引:
mongoCollection.Metadata.DropIndex("_UserName_");
下面提供删除除默认索引外其他全部索引的方法:
public void DropAllIndex()
{
var listIndexes = mongoCollection.Metadata.Indexes.ToList();
for (int i = 0; i < listIndexes.Count; i++)
{
if (listIndexes[i].Key != "_id_")
{
mongoCollection.Metadata.DropIndex(listIndexes[i].Key);
}
}
}
三、索引的效率
MongoDB的索引到底能不能提高查询效率呢?我们在这里通过一个例子来测试。比较同样的数据在无索引和有索引的情况下的查询速度。
首先,我们通过这样一个方法插入10W条数据:
public void InsertBigData()
{
var random = new Random();
for (int i = 1; i < 100000; i++)
{
Document doc = new Document();
doc["ID"] = i;
doc["Data"] = "data" + random.Next(100000);
mongoCollection.Save(doc);
}
Console.WriteLine("当前有" + mongoCollection.FindAll().Documents.Count() + "条数据");
}
然后,实现一个方法用来创建索引:
public void CreateIndexForData()
{
mongoCollection.Metadata.CreateIndex(new Document { { "Data", 1 } }, false);
}
还有排序的方法:
{
mongoCollection.FindAll().Sort(new Document { { "Data", 1 } });
}
运行测试代码如下:
static void Main(string[] args)
{
IndexBLL indexBll = new IndexBLL();
indexBll.DropAllIndex();
indexBll.DeleteAll();
indexBll.InsertBigData();
Stopwatch watch1 = new Stopwatch();
watch1.Start();
for (int i = 0; i < 1; i++) indexBll.SortForData();
Console.WriteLine("无索引排序执行时间:" + watch1.Elapsed);
indexBll.CreateIndexForData();
Stopwatch watch2 = new Stopwatch();
watch2.Start();
for (int i = 0; i < 1; i++) indexBll.SortForData();
Console.WriteLine("有索引排序执行时间:" + watch2.Elapsed);
}
最后执行程序查看结果: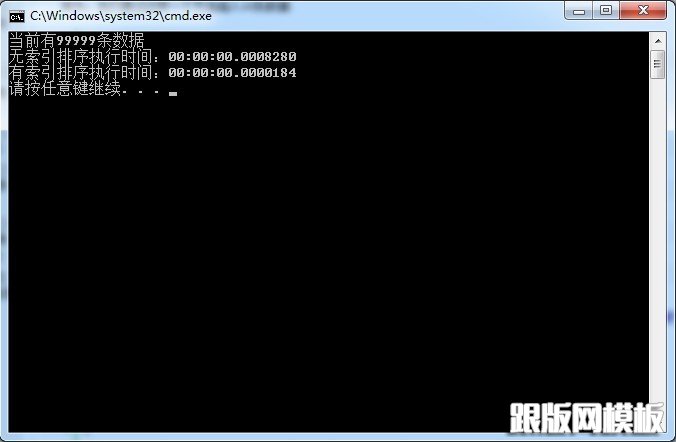
多次测试表明在有索引的情况下,查询效率要高于无索引的效率。
作者:李盼(Lipan)
出处:[Lipan] (http://www.cnblogs.com/lipan/)
相关文章
 MongoDB学习笔记(五) MongoDB文件存取操作由于MongoDB的文档结构为BJSON格式(BJSON全称:Binary JSON),而BJSON格式本身就支持保存二进制格式的数据,因此可以把文件的二进制格式的数据直接保存到Mongo
MongoDB学习笔记(五) MongoDB文件存取操作由于MongoDB的文档结构为BJSON格式(BJSON全称:Binary JSON),而BJSON格式本身就支持保存二进制格式的数据,因此可以把文件的二进制格式的数据直接保存到Mongo- MongoDB学习笔记(四) 用MongoDB的文档结构描述数据关系MongoDB的集合(collection)可以看做关系型数据库的表,文档对象(document)可以看做关系型数据库的一条记录。但两者并不完全对等
- MongoDB学习笔记(三) 在MVC模式下通过Jqgrid表格操作MongoDB数据下面我们将逐步讲解怎么在MVC模式下将MongoDB数据读取,并展示在前台Jqgrid表格上。这个“简易系统”的基本设计思想是这样的:我们在视图层展示表格,Jqgrid相关
- MongoDB学习笔记(二) 通过samus驱动实现基本数据操作传统的关系数据库一般由数据库(database)、表(table)、记录(record)三个层次概念组成,MongoDB是由(database)、集合(collection)、文档对象(document
 MongoDB学习笔记(一) MongoDB介绍与安装方法最近开始学习非关系型数据库MongoDB,却在博客园上找不到比较系统的教程,很多资料都要去查阅英文网站,效率比较低下。本人不才,借着自学的机会把心得体会都记
MongoDB学习笔记(一) MongoDB介绍与安装方法最近开始学习非关系型数据库MongoDB,却在博客园上找不到比较系统的教程,很多资料都要去查阅英文网站,效率比较低下。本人不才,借着自学的机会把心得体会都记- MongoDB 内存使用情况分析都说 MongoDB 是个内存大户,但是怎么知道它到底用了多少内存呢
 网站无法加载woff字体文件的解决办法?有客户反馈在安装网站后,woff、woff2字体无法加载,导致无法显示图标文件,这种情况要怎么解决呢? 这是因为服务器IIS默认是没有SVG,WOFF,WOFF2这几个文件类型的扩展的,
网站无法加载woff字体文件的解决办法?有客户反馈在安装网站后,woff、woff2字体无法加载,导致无法显示图标文件,这种情况要怎么解决呢? 这是因为服务器IIS默认是没有SVG,WOFF,WOFF2这几个文件类型的扩展的, 网站服务器不支持.7z文件下载的解决方法7-Zip是一款号称有着现今最高压缩比的压缩软件,它不仅支持独有的7z文件格式,而且还支持各种其它压缩文件格式,其中包括ZIP, RAR, CAB, GZIP, BZIP2和TAR。此软件压缩的压
网站服务器不支持.7z文件下载的解决方法7-Zip是一款号称有着现今最高压缩比的压缩软件,它不仅支持独有的7z文件格式,而且还支持各种其它压缩文件格式,其中包括ZIP, RAR, CAB, GZIP, BZIP2和TAR。此软件压缩的压