理解web服务器和数据库的负载均衡以及反向代理
时间:2016-09-25但是若该网站平均每秒的请求是200多次,那么问题就来了:这已经是最好的web服务器了,我该怎么办?同样的情景也适用于数据库。要解决这种问题,就需要了解“负载均衡”的原理了。
web服务器如何做负载均衡
为web服务器做负载均衡适用的的较多的方式是DNS重定向和反向代理,其他的方式原理也是很类似。
我们多次ping一下百度,会发现回复的IP会有所不同,例如第一次的结果为:
正在 Ping baidu.com [220.181.111.86] 具有 32 字节的数据:
来自 220.181.111.86 的回复: 字节=32 时间=27ms TTL=51
来自 220.181.111.86 的回复: 字节=32 时间=27ms TTL=51
来自 220.181.111.86 的回复: 字节=32 时间=27ms TTL=51
过一会再Ping一次,结果可能就变了:
正在 Ping baidu.com [220.181.111.85] 具有 32 字节的数据:
来自 220.181.111.85 的回复: 字节=32 时间=27ms TTL=51
来自 220.181.111.85 的回复: 字节=32 时间=27ms TTL=51
来自 220.181.111.85 的回复: 字节=32 时间=29ms TTL=51
使用nslookup命令可以看到多个ip与baidu.com对应。在这里用到的就是DNS重定向技术,原理很简单:DNS服务器保存某域名对应的多个IP,客户端发出DNS请求时DNS服务器根据算法将IP发回给客户端;发送回的一般是一个IP地址集合,但是每次的排序不同,第一次的第一个IP为201.11.11.1,第二次的第一个可能是201.11.11.2,客户端使用的是第一个IP――简单地说,就是客户端每次获取的域名的IP可能不同。不同的IP对应不同的web服务器,但是这些web服务器的内容应该是一样的。
我们从下图理解反向代理:
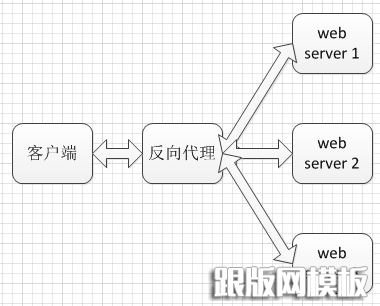
客户端向反向代理发送HTTP请求报文(若该网站有域名,域名的IP是反向代理服务器的外网IP),反向代理将请求报文随机发送给一个web服务器,web服务器将HTTP响应报文发送给反向代理,反向代理再将这报文返回给客户端。既然这样简单,我们就可以着手实现一个简单的反向代理。
在linux mint 15 下安装apache和nginx服务器,在apache的80端口的文档根目录下创建文件index.html,内容如下:
<html>
<head>
<title>index</title>
</head>
<body>
<h1>hello, i am apache</h1>
</body>
</html>
在nginx的8080端口的文档根目录下创建文件index.html,内容如下:
<html>
<head>
<title>index</title>
</head>
<body>
<h1>hello, i am nginx</h1>
</body>
</html>
创建源文件simple_reverse_proxy.py,内容如下:
#!/usr/bin/python
#-*-encoding:utf8-*-
'''
这是一个简单的反向代理服务器
'''
import BaseHTTPServer
import urllib2
HOST_NAME = '127.0.0.1'
PORT_NUMBER = 8081 #端口
SERVER_URL=('http://127.0.0.1:80','http://127.0.0.1:8080')
server_choice = 0
class MyHandler(BaseHTTPServer.BaseHTTPRequestHandler):
def do_GET(s):
"""response to a GET request"""
global server_choice
url = SERVER_URL[server_choice]
print url
server_choice = (server_choice + 1) % 2
headers = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'}
try:
req = urllib2.Request(url, None, headers)
response = urllib2.urlopen(req)
html = response.read()
#print html
s.send_response(200);
s.send_header("Content-type", "text/html")
s.end_headers()
s.wfile.write(html)
except:
s.send_response(404);
s.send_header("Content-type", "text/html")
s.end_headers()
s.wfile.write('<h2>404</h2>')
if __name__ == '__main__':
server_class = BaseHTTPServer.HTTPServer
httpd = server_class((HOST_NAME, PORT_NUMBER), MyHandler)
try:
httpd.serve_forever()
except KeyboardInterrupt:
pass
httpd.server_close()
启动apache、nginx,并运行simple_reverse_proxy.py。我们在浏览器中打开http://127.0.0.1:8081,我们可以看到:

刷新一下可以看到:
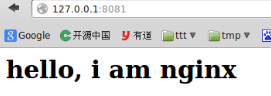
而simple_reverse_proxy.py会有以下信息输出:
bash >> ./simple_reverse_proxy.py
http://127.0.0.1:80
127.0.0.1 - - [05/Sep/2013 19:25:02] "GET / HTTP/1.1" 200 -
http://127.0.0.1:8080
127.0.0.1 - - [05/Sep/2013 19:25:43] "GET / HTTP/1.1" 200 -
当然,开源世界里已经有很多优秀的反向代理服务器了,例如Nginx。
只要理解了反向代理的原理,更复杂的架构也容易去实现。
数据库的负载均衡
对于大型网站,一个数据库系统肯定会遇到无法负担大量的读请求、写请求的情况。那么我们怎么来通过负载均衡来实现高并发的读写请求呢?
这其中一个很好的方法就是读写分离:将原本针对一个数据库服务器的读写请求分成读请求和写请求,向一个(或者多个)数据库服务器发送写请求,向另外一个(或多个)服务器发送读请求,这可以明显的提高响应时间。不过其中有一个难点,就是必须保持多个数据库服务器中的数据是一致的,不用担心,很多数据库系统已经实现了这个功能。下面是一个架构示例: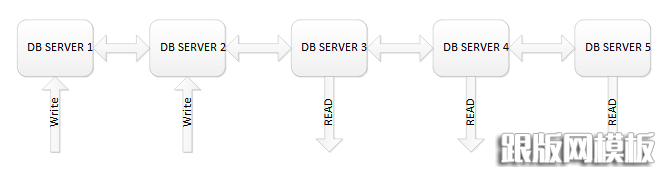
上图中其实有一个写写冲突的问题,想象以下场景:
该系统用于存放某网站的用户注册信息,该网站不允许用户名相同,且以用户名为唯一主键,所以在单数据库架构中必须涉及到事务的处理。现在在这个负载均衡的数据库架构中,用户A要注册用户名为xiaoming,这个写请求分配给了db server 1;与此同时用户B同样注册用户名xiaoming,如果写请求分配给了db server1,就不会有问题发生,可是如果分配给db server 2呢?两个db server分别存放了不同用户的用户名相同的用户信息!解决的方法很简单,写请求的分配不能用随机算法,应该使用哈希映射,例如注册的用户名首字母为x时,写请求分配各 db server2,其他写请求一律分配给db server 1。
另外一个问题,这种架构为开发应用提供了很大的灵活性,就是这种架构不适用于某些ORM框架,解决方法就是在这个架构上再加上一层――“数据库代理”。例如对于MySQL,就有MySQL Proxy这样的解决方案。
相关文章
 IIS中使用的ISAPI_Rewrite Full版本做反向代理详解代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外
IIS中使用的ISAPI_Rewrite Full版本做反向代理详解代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外 使用nginx来负载均衡 本文在window与linux下配置nginx实现负载使用nginx来负载均衡,本文在window与linux下配置nginx实现负载
使用nginx来负载均衡 本文在window与linux下配置nginx实现负载使用nginx来负载均衡,本文在window与linux下配置nginx实现负载 windows使用nginx实现网站负载均衡测试实例如果你关注过nginx,必定知道nginx这个软件有什么用的,如果你的网站访问量越来越高,一台服务器已经没有办法承受流量压力,那就增多几台服务器来做负载吧。
windows使用nginx实现网站负载均衡测试实例如果你关注过nginx,必定知道nginx这个软件有什么用的,如果你的网站访问量越来越高,一台服务器已经没有办法承受流量压力,那就增多几台服务器来做负载吧。- 封80端口应对策略 Nginx反向代理For WIN2003超级傻瓜式配置封80应对策略,Nginx反向代理ForWIN2003超级傻瓜式配置!
- Nginx 简单的负载均衡配置示例Nginx 简单的负载均衡配置示例,需要的朋友可以参考下。
- Nginx 安装笔记(含PHP支持、虚拟主机、反向代理负载均衡)Nginx安装简记(含PHP支持、虚拟主机、反向代理负载均衡) Nginx,据说高性能和稳定性比Apache还牛,并发连接处理能力强,低系统资源消耗。目前已有250多万web站点
 网站无法加载woff字体文件的解决办法?有客户反馈在安装网站后,woff、woff2字体无法加载,导致无法显示图标文件,这种情况要怎么解决呢? 这是因为服务器IIS默认是没有SVG,WOFF,WOFF2这几个文件类型的扩展的,
网站无法加载woff字体文件的解决办法?有客户反馈在安装网站后,woff、woff2字体无法加载,导致无法显示图标文件,这种情况要怎么解决呢? 这是因为服务器IIS默认是没有SVG,WOFF,WOFF2这几个文件类型的扩展的, 网站服务器不支持.7z文件下载的解决方法7-Zip是一款号称有着现今最高压缩比的压缩软件,它不仅支持独有的7z文件格式,而且还支持各种其它压缩文件格式,其中包括ZIP, RAR, CAB, GZIP, BZIP2和TAR。此软件压缩的压
网站服务器不支持.7z文件下载的解决方法7-Zip是一款号称有着现今最高压缩比的压缩软件,它不仅支持独有的7z文件格式,而且还支持各种其它压缩文件格式,其中包括ZIP, RAR, CAB, GZIP, BZIP2和TAR。此软件压缩的压