百度蜘蛛3.0已经更新 我们来看看到底有什么进步
时间:2016-06-25百度蜘蛛(BaiduSpider)现在已经升级为了3.0,很多站长反应其自身的网站抓取速度已经提升很多了,这到底是怎么回事呢?现在就带大家一起来看看百度的这次更新。
百度蜘蛛,简单的说:就是百度搜索引擎的一个自动抓取的程序系统。这个爬虫系统作用主要还是访问和收集整理互联网上的网页、图片、视频等内容物。然后根据系统中自己的理解,来分门别类为这些内容物,建立索引数据库,。这样就可以使用户能在百度的搜索引擎中直接通过各种的关键词来搜索到你网站的网页、图片、视频等内容物。总得来说就是记录经过不同站点和内容后,进行数据收集和分析后,建立各种各样的索引库。
Baidu Spider上一次大规模的升级还要追溯到2010年。
就在那个时候,中国的互联网资源急剧扩张膨胀,从百亿规模已经快速的扩大到千亿量级,因此百度spider系统也需要进行不断的重构,现在从计算机的单机互联也成功的转变为计算机的分布式计算。
但是有一个很大的缺点:延时严重!
而此次重构是把当前离线、全量计算为主的系统,改造成实时、增量计算可以全实时进行调度的系统,迎合万亿规模的数据进行实时读写,可以收录大部分的网页,速度提升80%!
新的蜘蛛模型如图:
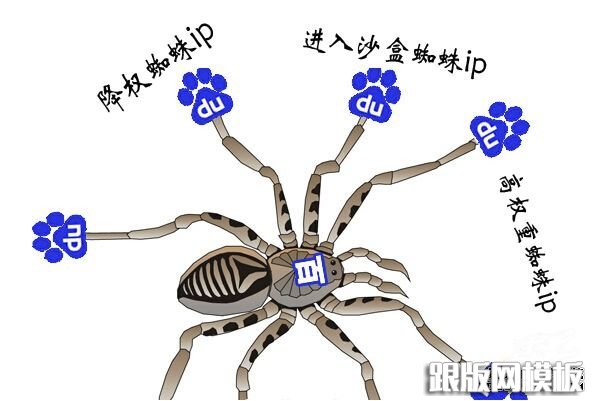
Baidu Spider3.0
一、链接
如今的sipder每天能够发现的新链接也已经在500亿左右的量级了,特别是在百度站长平台提交链接是其中最为高效的,特此,工程师提醒站长不要过度提交链接,尤其是低质链接,这样才能达到更好更及时的收录效果。
二、链接抓取方面
策略上,开发了更强大的机器学习模型,来进行链接的质量预测,对数据库中的所有链接会自动的进行全局排序,对于自身有价值链接的重启率会显著的进行大幅提高!
在蜘蛛的架构上,和计算性能的强劲提升,对每天网络世界上新增的数百亿模块的链接,实时完成后台计算,一般的延时不到1秒;并且开发出了更加强大的计算机存储系统,面对万亿规模的数据也可以做到实时的读写命令。
三、时效性页面方面
中长尾关键词站长的福音!现在百度针对众多原创性时效资源,从原来的优先对新浪、网易等新闻大站进行抓取,扩大到覆盖全网的新闻、博客、论坛等站点进行快速抓取,所有的大小网站都站在同一起跑线。
打破以前平稳抓取模型,更新为采用按需进行多线抓取的机制,对于很多有时效性新资源,可以做到瞬间抓取收录。
目前,我现在每天收录的时效性资源规模,也必须比以前扩大至少的3倍。应该现在百度的处理能力已经达到了近1亿量级!
四、死链方面
全新的死链识别模型,能识别各种协议死链、内容死链、跳转死链等低质网页。
其中无效低质网页(如被黑),通过百度站长平台提交,可加快检索屏蔽的过程。
五、建库方面
百度在索引展现时效性会大幅的提升,以前原来大约是是10天左右,现在已经提升一般左右!也就是说现在的新闻4天就会过百度默认的新闻时效。
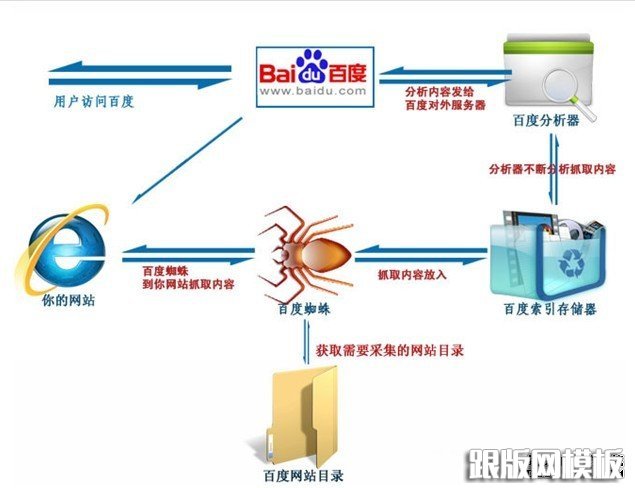
Spider3.0时代
站长平台链接提交工具,可以让抓取比以前更快!
站长平台死链提交工具,也可以让检索这些死链时屏蔽过程更加简化!
相关文章
 百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没
百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没 百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜
百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜 百度推出飓风算法,严厉打击恶劣采集百度搜索于近日推出飓风算法,旨在严厉打击以恶劣采集为内容主要来源的网站,同时百度搜索将从索引库中彻底清除恶劣采集链接,给优质原创内容提供更多展示机会,
百度推出飓风算法,严厉打击恶劣采集百度搜索于近日推出飓风算法,旨在严厉打击以恶劣采集为内容主要来源的网站,同时百度搜索将从索引库中彻底清除恶劣采集链接,给优质原创内容提供更多展示机会,- 百度https认证提示"请将您的http站点301重定向到https站点"的解决办法最近想把一个网站改造成https访问,但是一些都做好了,去百度站长平台认证https,结果怎么提交都是出现请将您的http站点301重定向到https站点,在百度站长社区提
 https站点如何建设才能对百度友好2015年5月25日,百度站长平台发布公告,宣布全面放开对https站点的收录,https站点不再需要做任何额外工作即可被百度抓收。采用了本文之前建议的https站点可以关
https站点如何建设才能对百度友好2015年5月25日,百度站长平台发布公告,宣布全面放开对https站点的收录,https站点不再需要做任何额外工作即可被百度抓收。采用了本文之前建议的https站点可以关 【百度官方说法】关于闭站保护,这些问题你一定要知道反馈中心经常收到站长们对闭站保护的提问,很多问题值班童靴已经是强调了再强调的,学院君特整理了一篇最全答疑,有问题的站长们看这里: 1 、闭站保护的通过时
【百度官方说法】关于闭站保护,这些问题你一定要知道反馈中心经常收到站长们对闭站保护的提问,很多问题值班童靴已经是强调了再强调的,学院君特整理了一篇最全答疑,有问题的站长们看这里: 1 、闭站保护的通过时