搜索官方的一篇相关性文章分享
时间:2016-04-11议程
概述
检索词
用户的信息需求
网页的自有信息
网页的附属信息
相关性的计算框架
概述
相关性的表象
检索词与被检索网页的相关联程度
相关性的真实意义
用户信息需求与结果网页所提供的信息的重合度
相关性涉及的因素
检索词
用户信息需求
网页自有信息
网页附属信息
检索结果的显示方式
网页与普通文本的不同:异质性
来源不单一
新闻记者
研究人员
商业人士
个人
用途不单一
新闻
商业及产品信息
个人爱好
娱乐信息
研究及学术信息
产生方式多样化
手工及发布系统
动态与静态
时效性:不同时间产生
动态性:可随时间变化
欺骗与造假
检索词
语义
实体名
人名
地名
公司及机构名
商品及服务名
其他专有名词名
普通名词
其他类别名
其他
信息格式
语种
结构化,非结构化
信息类别
研究信息
商品及服务信息
宗教文化
娱乐信息
新闻
个人信息
检索词格式
数值
布尔运算(AND, OR, NOT)
特殊语法(网站检索,类别检索,filetype,linkto)
Rank Query
检索词 - 相关性处理
实体名的判定用于网站首页加权
检索词分类用于与网站网页分类结合加权
信息类别的分类与统计
行业与地域的分类与统计
检索格式的分析
单语素与多语素
AND检索的研究
网页分类两种体系
按网页结构信息分类(主页,频道页,检索页,错误页,租用页…)
按网页内容主题分类(体育,保健,娱乐,教育..)
用户的信息需求
检索任务的多样性
确定的特定信息的查询
知识获取式的浏览
目的不明确的浏览:在过程中形成目的
检索词的语义多样性
检索范围的不确定性
信息种类
行业,地域,等等
检索成功的标准不一
实体名,有特定网站,- 导航型查询
实体名,无特定网站,有相关网站 - 事务型查询
一般信息,无网站信息,许多网页提及 - 信息型查询
一般信息,无网站信息,很少网页提及 - 信息型查询
个人知识结构与兴趣
个人的信息精确性和多样性要求程度
用户的信息需求- 相关性设计
结果首页尽量显示多个类型的网页
功能,多分类和垂直搜索结果整合设计
个性化排序设计
检索日志的后台分析
用户行为数据挖掘
网页的自有信息(属性)
文本信息:字,词,短语,句子,段落,篇章
文本特征信息
标题
正文
文章长度
知识量
其他特征:黑体,链接,等等
结构信息
导航(一级导航,二级导航。。。)
广告(文字链,banner)
图片
引用(博客,论坛),
版权说明等等
语义信息
文章类型:综述/细节,新闻,科技与研究,个人,特种文件链接
地域信息
行业信息
语种信息
网页的自有信息 - 相关性设计
切词一致性与准确性
正文内容的歧义消解,未登录词识别
查询词切分和正文切分的一致性问题处理
文本特征提取与权重指定
标题的准确性
标题提取规则:URL,标题等
实际标题
标题的真实性
标题长度截取
标题验证去除人工错误
标题作弊判别
无正文的标题处理
正文的准确性
广告文字
网页模板文字
iframe处理
js 内容处理
正文的真实性
语义tag的引入
特征tag的权重和调整
文章长度的调整系数
对超长文章的修正
DOC,PPT,PDF处理
网页的自有信息 - 相关性设计
结构信息提取与处理
首页和频道首页的识别和标记,将使用网站PR
导航区的统计,识别和标记
用于首页识别,链接将不参与PR及外部锚文本的计算
网站附属页的统计,识别和标记
赋予网站相关的PR, 链接将不参与PR及外部锚文本的计算
广告链接的统计,识别和标记,将不参与PR及外部锚文本的计算
内容分析
通过特征统计结合手工方式进行网站分类
文章类型信息:新闻页的特殊标记
地域信息
行业及其他分类信息
中英文比例调整
网页的附属信息(属性)
网页本身的附属信息
URL:长度与级数,动态与静态
产生时间
网页文件大小
可连接程度
连通率
死链情况
内容的稳定性:
更新周期
生命周期
所属域名及网站特性
类别
权威性
网页由环境所产生的附属信息
在网站内的重要性:首页,频道,外部被链接数量
全局权威性:被别人的认可程度
时效性:距今时间
真实性:实际内容信息与文本和附属信息的吻合度
重复性:与其他网页内容的重合度
信息内容和质量:别人对内容的认可程度
用户的评价
深度和广度
网页的附属信息-相关性处理
时间信息参与排序
新闻页的倒排: 强影响
网页的时间因素:弱影响
不影响首页和频道首页
连通率与更新率参与排序
弱连通的减权
死链的减权
更新频度参与减权
网站特性
网站分类与检索词的吻合提高相关性
网站真实性参与相关性计算:
作弊连接网站的黑名单(Link Farm)
TrickRank
网站重要性:
网站DR(Domain Rank)
Block PR
计算站内PR,网站分别计算
计算站外PR,不考虑站内链接
排重和保留
镜像列表: PR和外部锚文本的传递
首页排重规则
内容排重规则
跳转的类型和规则: PR和外部锚文本的传递
外部锚文本的真实性
链接交换网站黑名单
正文验证去躁
相关性的计算框架
主要设计模式

有公式-相关性排序
无公式人工神经网络(MLR)
针对检索词和用户信息需求综合分析确定策略
人工和程序结合提高网页自有信息的提取和处理能力
提高锚文本包含的词质量,防止作弊
PR,DR,TR结合,提高网页权威性判定质量,保证首页,索引页靠前
增加网页附属信息参与排序
增加各因素之间的交叉验证
对部分高频词做手工调整(homony)
相关性排序的周边技术
下载
正文分析
切词
手工与程序分类
PR,DR,TR计算
锚文本词处理
遗传算法训练排序因子
概述
检索词
用户的信息需求
网页的自有信息
网页的附属信息
相关性的计算框架
概述
相关性的表象
检索词与被检索网页的相关联程度
相关性的真实意义
用户信息需求与结果网页所提供的信息的重合度
相关性涉及的因素
检索词
用户信息需求
网页自有信息
网页附属信息
检索结果的显示方式
网页与普通文本的不同:异质性
来源不单一
新闻记者
研究人员
商业人士
个人
用途不单一
新闻
商业及产品信息
个人爱好
娱乐信息
研究及学术信息
产生方式多样化
手工及发布系统
动态与静态
时效性:不同时间产生
动态性:可随时间变化
欺骗与造假
检索词
语义
实体名
人名
地名
公司及机构名
商品及服务名
其他专有名词名
普通名词
其他类别名
其他
信息格式
语种
结构化,非结构化
信息类别
研究信息
商品及服务信息
宗教文化
娱乐信息
新闻
个人信息
检索词格式
数值
布尔运算(AND, OR, NOT)
特殊语法(网站检索,类别检索,filetype,linkto)
Rank Query
检索词 - 相关性处理
实体名的判定用于网站首页加权
检索词分类用于与网站网页分类结合加权
信息类别的分类与统计
行业与地域的分类与统计
检索格式的分析
单语素与多语素
AND检索的研究
网页分类两种体系
按网页结构信息分类(主页,频道页,检索页,错误页,租用页…)
按网页内容主题分类(体育,保健,娱乐,教育..)
用户的信息需求
检索任务的多样性
确定的特定信息的查询
知识获取式的浏览
目的不明确的浏览:在过程中形成目的
检索词的语义多样性
检索范围的不确定性
信息种类
行业,地域,等等
检索成功的标准不一
实体名,有特定网站,- 导航型查询
实体名,无特定网站,有相关网站 - 事务型查询
一般信息,无网站信息,许多网页提及 - 信息型查询
一般信息,无网站信息,很少网页提及 - 信息型查询
个人知识结构与兴趣
个人的信息精确性和多样性要求程度
用户的信息需求- 相关性设计
结果首页尽量显示多个类型的网页
功能,多分类和垂直搜索结果整合设计
个性化排序设计
检索日志的后台分析
用户行为数据挖掘
网页的自有信息(属性)
文本信息:字,词,短语,句子,段落,篇章
文本特征信息
标题
正文
文章长度
知识量
其他特征:黑体,链接,等等
结构信息
导航(一级导航,二级导航。。。)
广告(文字链,banner)
图片
引用(博客,论坛),
版权说明等等
语义信息
文章类型:综述/细节,新闻,科技与研究,个人,特种文件链接
地域信息
行业信息
语种信息
网页的自有信息 - 相关性设计
切词一致性与准确性
正文内容的歧义消解,未登录词识别
查询词切分和正文切分的一致性问题处理
文本特征提取与权重指定
标题的准确性
标题提取规则:URL,标题等
实际标题
标题的真实性
标题长度截取
标题验证去除人工错误
标题作弊判别
无正文的标题处理
正文的准确性
广告文字
网页模板文字
iframe处理
js 内容处理
正文的真实性
语义tag的引入
特征tag的权重和调整
文章长度的调整系数
对超长文章的修正
DOC,PPT,PDF处理
网页的自有信息 - 相关性设计
结构信息提取与处理
首页和频道首页的识别和标记,将使用网站PR
导航区的统计,识别和标记
用于首页识别,链接将不参与PR及外部锚文本的计算
网站附属页的统计,识别和标记
赋予网站相关的PR, 链接将不参与PR及外部锚文本的计算
广告链接的统计,识别和标记,将不参与PR及外部锚文本的计算
内容分析
通过特征统计结合手工方式进行网站分类
文章类型信息:新闻页的特殊标记
地域信息
行业及其他分类信息
中英文比例调整
网页的附属信息(属性)
网页本身的附属信息
URL:长度与级数,动态与静态
产生时间
网页文件大小
可连接程度
连通率
死链情况
内容的稳定性:
更新周期
生命周期
所属域名及网站特性
类别
权威性
网页由环境所产生的附属信息
在网站内的重要性:首页,频道,外部被链接数量
全局权威性:被别人的认可程度
时效性:距今时间
真实性:实际内容信息与文本和附属信息的吻合度
重复性:与其他网页内容的重合度
信息内容和质量:别人对内容的认可程度
用户的评价
深度和广度
网页的附属信息-相关性处理
时间信息参与排序
新闻页的倒排: 强影响
网页的时间因素:弱影响
不影响首页和频道首页
连通率与更新率参与排序
弱连通的减权
死链的减权
更新频度参与减权
网站特性
网站分类与检索词的吻合提高相关性
网站真实性参与相关性计算:
作弊连接网站的黑名单(Link Farm)
TrickRank
网站重要性:
网站DR(Domain Rank)
Block PR
计算站内PR,网站分别计算
计算站外PR,不考虑站内链接
排重和保留
镜像列表: PR和外部锚文本的传递
首页排重规则
内容排重规则
跳转的类型和规则: PR和外部锚文本的传递
外部锚文本的真实性
链接交换网站黑名单
正文验证去躁
相关性的计算框架
主要设计模式
有公式-相关性排序
无公式人工神经网络(MLR)
针对检索词和用户信息需求综合分析确定策略
人工和程序结合提高网页自有信息的提取和处理能力
提高锚文本包含的词质量,防止作弊
PR,DR,TR结合,提高网页权威性判定质量,保证首页,索引页靠前
增加网页附属信息参与排序
增加各因素之间的交叉验证
对部分高频词做手工调整(homony)
相关性排序的周边技术
下载
正文分析
切词
手工与程序分类
PR,DR,TR计算
锚文本词处理
遗传算法训练排序因子
相关文章
 百度https认证提示"请将您的http站点301重定向到https站点"的解决办法最近想把一个网站改造成https访问,但是一些都做好了,去百度站长平台认证https,结果怎么提交都是出现请将您的http站点301重定向到https站点,在百度站长社区提
百度https认证提示"请将您的http站点301重定向到https站点"的解决办法最近想把一个网站改造成https访问,但是一些都做好了,去百度站长平台认证https,结果怎么提交都是出现请将您的http站点301重定向到https站点,在百度站长社区提 【百度官方说法】关于闭站保护,这些问题你一定要知道反馈中心经常收到站长们对闭站保护的提问,很多问题值班童靴已经是强调了再强调的,学院君特整理了一篇最全答疑,有问题的站长们看这里: 1 、闭站保护的通过时
【百度官方说法】关于闭站保护,这些问题你一定要知道反馈中心经常收到站长们对闭站保护的提问,很多问题值班童靴已经是强调了再强调的,学院君特整理了一篇最全答疑,有问题的站长们看这里: 1 、闭站保护的通过时- 百度链接提交主动推送后不收录的原因自从百度站长平台开放了百度链接主动推送接口以后,很多站长都开始使用百度开放的这个主动推送接口来推送网站的最新内容,但是在使用这个推送接口的时候,大家肯
 解密蜘蛛池的工作原理很多人认为外链对SEO没效果了,还有很多人看到发布外链越来越难了,没有论坛、平台不允许留锚文本,那么蜘蛛池程序可以完美的替你解决网站 外链SEO 的问题,蜘蛛
解密蜘蛛池的工作原理很多人认为外链对SEO没效果了,还有很多人看到发布外链越来越难了,没有论坛、平台不允许留锚文本,那么蜘蛛池程序可以完美的替你解决网站 外链SEO 的问题,蜘蛛- 网站权重和网站的关系怎么把网站的排名靠前? 应该把网站的权重弄高一些,因为只有权重高的网站,搜索引擎才能喜欢,这样你的网站排名就会靠前。 不过权重高不一定代表排名高, 因为也
- 【官方说法】官网保护工具如何通过申请?官网保护工具自推出以来,受到广大站长们关注,后台申请数据量更是高达 20 多万,审核这么大量的需求词,审核员也发现了一些问题,希望再次给到站长们提醒,请拿
 百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没被QQ和微信
百度站长平台:该站点为低质站点,暂不可添加,请持续优化后,再行尝试最近新抢注了一个域名,到百度站长平台添加网站时候提示:该站点为低质站点,暂不可添加,请持续优化后,再行尝试。这种情况是啥问题? 经过一番查看,此域名没被QQ和微信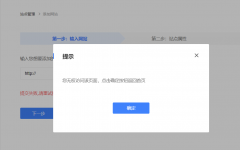 百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜了一下,也
百度站长平台“你无权访问该页面,点击确定按钮返回首页”小编在百度站长平台添加网站时候,提示:你无权访问该页面,点击确定按钮返回首页,如下图所示: 小编觉得很奇怪,因为之前添加了十多个网站都没有问题,百度搜了一下,也