MySQL�����Ż���ʮ��ʵս����
ʱ�䣺2016-04-04���죬���ݿ�IJ���Խ��Խ��Ϊ����Ӧ�õ�����ƿ���ˣ�������WebӦ���������ԡ��������ݿ�����ܣ��Ⲣ��ֻ��DBA����Ҫ���ĵ��£�����������dz���Ա��Ҫȥ��ע�����顣������ȥ������ݿ���ṹ���Բ������ݿ�ʱ�������Dz��ʱ��SQL��䣩�����Ƕ���Ҫע�����ݲ��������ܡ�������Dz��ὲ�����SQL�����Ż�����ֻ�����MySQL��һWebӦ���������ݿ⡣ϣ���������Щ�Ż����ɶ������á�
1. Ϊ��ѯ�����Ż���IJ�ѯ
�������MySQL�������������˲�ѯ���档�������������Ч�ķ���֮һ���������DZ�MySQL�����ݿ����洦���ġ����кܶ���ͬ�IJ�ѯ��ִ���˶�ε�ʱ����Щ��ѯ����ᱻ�ŵ�һ�������У���������������ͬ�IJ�ѯ�Ͳ��ò�������ֱ�ӷ��ʻ������ˡ�
��������Ҫ�������ǣ����ڳ���Ա��˵����������Ǻ����ױ����Եġ���Ϊ������ijЩ��ѯ������MySQL��ʹ�û��档�뿴�����ʾ����

��������SQL���IJ����� CURDATE() ��MySQL�IJ�ѯ�������������������á����ԣ��� NOW() �� RAND() ������������������SQL���������Ὺ����ѯ���棬��Ϊ��Щ�����ķ����ǻ�����ױ�ġ����ԣ�������Ҫ�ľ�����һ������������MySQL�ĺ������Ӷ��������档
2. EXPLAIN ��� SELECT ��ѯ
ʹ�� EXPLAIN �ؼ��ֿ�������֪��MySQL����δ������SQL���ġ�������������IJ�ѯ�����DZ��ṹ������ƿ����
EXPLAIN �IJ�ѯ�������������������������������õģ�������ݱ�����α������������……�ȵȣ��ȵȡ�
��һ�����SELECT��䣨�Ƽ���ѡ�Ǹ���ӵģ��ж�����ӵģ����ѹؼ���EXPLAIN�ӵ�ǰ�档�����ʹ��phpmyadmin��������¡�Ȼ����ῴ��һ�ű�����������ʾ���У��������Ǽ�����group_id�����������б����ӣ�

���ǿ��Կ�����ǰһ�������ʾ������ 7883 �У�����һ��ֻ���������������� 9 �� 16 �С��鿴rows�п����������ҵ�DZ�ڵ��������⡣
3. ��ֻҪһ������ʱʹ�� LIMIT 1
�����ѯ������Щʱ�����Ѿ�֪�����ֻ����һ�����������Ϊ�������Ҫȥfetch�α꣬������Ҳ����ȥ��鷵�صļ�¼����
����������£����� LIMIT 1 �����������ܡ�����һ����MySQL���ݿ���������ҵ�һ�����ݺ�ֹͣ�����������Ǽ������������һ�����ϼ�¼�����ݡ�
�����ʾ����ֻ��Ϊ����һ���Ƿ���“�й�”���û��������ԣ�����Ļ��ǰ��ĸ���Ч�ʡ�����ע�⣬��һ������Select *���ڶ�����Select 1��

4. Ϊ�����ֶν�����
��������һ�����Ǹ���������Ψһ���ֶΡ��������ı��У���ij���ֶ�����Ҫ�ᾭ����������������ô����Ϊ�佨�������ɡ�

����ͼ����Կ����Ǹ������ִ� “last_name LIKE ‘a%’”��һ���ǽ���������һ����û�����������ܲ���4�����ҡ�
���⣬��Ӧ��Ҳ��Ҫ֪��ʲô���������Dz���ʹ�������������ġ����磬������Ҫ��һƪ�������������һ����ʱ���磺 “WHERE post_content LIKE ‘%apple%’”������������û������ġ��������Ҫʹ��MySQLȫ������ �����Լ���һ������������˵�������ؼ��ʻ���Tagʲô�ģ�
5. ��Join����ʱ��ʹ���൱���͵���������������
������Ӧ�ó����кܶ� JOIN ��ѯ����Ӧ��ȷ����������Join���ֶ��DZ����������ġ�������MySQL�ڲ�������Ϊ���Ż�Join��SQL���Ļ��ơ�
���ң���Щ������Join���ֶΣ�Ӧ������ͬ�����͵ġ����磺�����Ҫ�� DECIMAL �ֶκ�һ�� INT �ֶ�Join��һ��MySQL����ʹ�����ǵ�������������ЩSTRING���ͣ�����Ҫ����ͬ���ַ������С������������ַ����п��ܲ�һ����

6. ǧ��Ҫ ORDER BY RAND()
����ҷ��ص������У������һ�����ݣ��治֪��˭�����������÷������ܶ����ֺ�ϲ�������á�����ȷ���˽��������ж�ô���µ��������⡣
����������ѷ��ص������д����ˣ�����N�ַ������Դﵽ���Ŀ�ġ�����ʹ��ֻ��������ݿ�����ܳ�ָ�������½�������������ǣ�MySQL��ò�ȥִ��RAND()�������ܺ�CPUʱ�䣩����������Ϊ��ÿһ�м�¼ȥ���У�Ȼ���ٶ�����������������Limit 1Ҳ�����£���ΪҪ����
�����ʾ���������һ����¼

7. ���� SELECT *
�����ݿ������Խ������ݣ���ô��ѯ�ͻ���Խ�������ң����������ݿ��������WEB����������\̨\�����ķ������Ļ�������������紫��ĸ��ء�
���ԣ���Ӧ������һ����Ҫʲô��ȡʲô�ĺõ�ϰ�ߡ�

8. ��ԶΪÿ�ű�����һ��ID
����Ӧ��Ϊ���ݿ����ÿ�ű�������һ��ID��Ϊ��������������õ���һ��INT�͵ģ��Ƽ�ʹ��UNSIGNED�������������Զ����ӵ�AUTO_INCREMENT��־��
�������� users ����һ�������� “email”���ֶΣ���Ҳ��������Ϊ������ʹ�� VARCHAR ��������������ʹ�õ������½������⣬����ij����У���Ӧ��ʹ�ñ���ID������������ݽṹ��
���ң���MySQL���������£�����һЩ������Ҫʹ������������Щ����£����������ܺ����ñ�÷dz���Ҫ�����磬��Ⱥ������……
�����ֻ��һ����������⣬�Ǿ���“������”��“���”��Ҳ����˵���������������ͨ�����ɸ���ı����������ɡ����ǰ�����������“���”�����磺��һ��“ѧ����”��ѧ����ID����һ��“�γ̱�”�пγ�ID����ô��“�ɼ���”����“������”�ˣ��������ѧ�����Ϳγ̱����ڳɼ����У�ѧ��ID�Ϳγ�ID��“���”�乲ͬ���������
9. ʹ�� ENUM ������ VARCHAR
ENUM �����Ƿdz���ͽ��յġ���ʵ���ϣ��䱣����� TINYINT�������������ʾΪ�ַ���������һ����������ֶ�����һЩѡ���б�����൱��������
�������һ���ֶΣ�����“�Ա�”��“����”��“����”��“״̬”��“����”����֪����Щ�ֶε�ȡֵ�������ҹ̶��ģ���ô����Ӧ��ʹ�� ENUM ������ VARCHAR��
MySQLҲ��һ��“����”������ʮ������������ôȥ������֯��ı��ṹ��������һ�� VARCHAR �ֶ�ʱ������������������ij� ENUM ���͡�ʹ�� PROCEDURE ANALYSE() ����Եõ���صĽ��顣
10. �� PROCEDURE ANALYSE() ȡ�ý���
PROCEDURE ANALYSE() ���� MySQL ����ȥ��������ֶκ���ʵ�ʵ����ݣ��������һЩ���õĽ��顣ֻ�б�����ʵ�ʵ����ݣ���Щ����Ż������ã���ΪҪ��һЩ��ľ�������Ҫ��������Ϊ�����ġ�
���磬����㴴����һ�� INT �ֶ���Ϊ���������Ȼ����û��̫������ݣ���ô��PROCEDURE ANALYSE()�Ὠ���������ֶε����ij� MEDIUMINT ��������ʹ����һ�� VARCHAR �ֶΣ���Ϊ���ݲ��࣬����ܻ�õ�һ����������ij� ENUM �Ľ��顣��Щ���飬���ǿ�����Ϊ���ݲ����࣬���Ծ������þͲ�����
��phpmyadmin�������ڲ鿴��ʱ����� “Propose table structure” ���鿴��Щ����
һ��Ҫע�⣬��Щֻ�ǽ��飬ֻ�е���ı��������Խ��Խ��ʱ����Щ����Ż���ȷ��һ��Ҫ��ס��������������������ˡ�
11. �����ܵ�ʹ�� NOT NULL
��������һ�����ر��ԭ��ȥʹ�� NULL ֵ����Ӧ������������ֶα��� NOT NULL���⿴���������е����飬�����¿���
���ȣ��������Լ�“Empty”��“NULL”�ж������������INT���Ǿ���0��NULL����������������֮��û��ʲô������ô��Ͳ�Ҫʹ��NULL������֪������ Oracle �NULL �� Empty ���ַ�����һ���ģ�)
��Ҫ��Ϊ NULL ����Ҫ�ռ䣬����Ҫ����Ŀռ䣬���ң�������бȽϵ�ʱ����ij��������ӡ� ��Ȼ�����ﲢ����˵��Ͳ���ʹ��NULL�ˣ���ʵ����Ǻܸ��ӵģ���Ȼ����Щ����£�����Ҫʹ��NULLֵ��
����ժ��MySQL�Լ����ĵ���

12. Prepared Statements
Prepared Statements����洢���̣���һ�������ں�̨��SQL��伯�ϣ����ǿ��Դ�ʹ�� prepared statements ��úܶ�ô�����������������ǰ�ȫ���⡣
Prepared Statements ���Լ��һЩ��õı������������Ա�����ij����ܵ�“SQLע��ʽ”��������Ȼ����Ҳ�����ֶ��ؼ�������Щ������Ȼ�����ֶ��ļ�����׳����⣬���Һܾ����ᱻ����Ա���ˡ�������ʹ��һЩframework����ORM��ʱ��������������һЩ��
�����ܷ��棬��һ����ͬ�IJ�ѯ��ʹ�ö�ε�ʱ�����Ϊ������ɹ۵��������ơ�����Ը���ЩPrepared Statements����һЩ��������MySQLֻ�����һ�Ρ�
��Ȼ���°汾��MySQL�ڴ���Prepared Statements��ʹ�ö��������ƣ��������ʹ�����紫��dz���Ч�ʡ�
��Ȼ��Ҳ��һЩ����£�������Ҫ����ʹ��Prepared Statements����Ϊ�䲻֧�ֲ�ѯ���档����˵�汾5.1��֧���ˡ�
��PHP��Ҫʹ��prepared statements������Բ鿴��ʹ���ֲmysqli ��չ ����ʹ�����ݿ����㣬�磺 PDO.

13. ����IJ�ѯ
����������£������ڵ�������Ľű���ִ��һ��SQL����ʱ����ij����ͣ������ֱ��û���SQL��䷵�أ�Ȼ����ij��������¼���ִ�С������ʹ�������ѯ���ı������Ϊ��
����������飬��PHP���ĵ�����һ���dz�������˵���� mysql_unbuffered_query() ������

�����Ǿ仰���������˵��mysql_unbuffered_query() ����һ��SQL��䵽MySQL��������mysql_query()һ��ȥ�Զ�fethch�ͻ�����������൱��Լ�ܶ�ɹ۵��ڴ棬��������Щ�������������IJ�ѯ��䣬���ң��㲻��Ҫ�ȵ����еĽ�������أ�ֻ��Ҫ��һ�����ݷ��ص�ʱ����Ϳ��Կ�ʼ���Ͽ�ʼ�����ڲ�ѯ����ˡ�
Ȼ���������һЩ���ơ���Ϊ��Ҫô�������ж����ߣ�������Ҫ�ڽ�����һ�εIJ�ѯǰ���� mysql_free_result() �����������ң� mysql_num_rows() �� mysql_data_seek() ����ʹ�á����ԣ��Ƿ�ʹ������IJ�ѯ����Ҫ��ϸ���ǡ�
14. ��IP��ַ��� UNSIGNED INT
�ܶ����Ա���ᴴ��һ�� VARCHAR(15) �ֶ�������ַ�����ʽ��IP���������ε�IP�����������������ţ�ֻ��Ҫ4���ֽڣ�����������ж������ֶΡ����ң����Ϊ�������ѯ�ϵ����ƣ������ǵ�����Ҫʹ��������WHERE������IP between ip1 and ip2��
���DZ���Ҫʹ��UNSIGNED INT����Ϊ IP��ַ��ʹ������32λ���������Ρ�
����IJ�ѯ�������ʹ�� INET_ATON() ����һ���ַ���IPת��һ�����Σ���ʹ�� INET_NTOA() ��һ������ת��һ���ַ���IP����PHP�У�Ҳ�������ĺ��� ip2long() �� long2ip()��

15. �̶����ȵı������
������е������ֶζ���“�̶�����”�ģ��������ᱻ��Ϊ�� “static” �� “fixed-length”�� ���磬����û���������͵��ֶΣ� VARCHAR��TEXT��BLOB��ֻҪ�����������һ����Щ�ֶΣ���ô������Ͳ���“�̶����Ⱦ�̬��”�ˣ�������MySQL ���������һ�ַ�����������
�̶����ȵı���������ܣ���ΪMySQL��Ѱ�û����һЩ����Ϊ��Щ�̶��ij����Ǻ���������һ�����ݵ�ƫ�����ģ����Զ�ȡ����ȻҲ��ܿ졣������ֶβ��Ƕ����ģ���ô��ÿһ��Ҫ����һ���Ļ�����Ҫ�����ҵ�������
���ң��̶����ȵı�Ҳ�����ױ�������ؽ���������Ψһ�ĸ������ǣ��̶����ȵ��ֶλ��˷�һЩ�ռ䣬��Ϊ�������ֶ��������ò��ã�������Ҫ������ô��Ŀռ䡣
ʹ��“��ֱ�ָ�”����������һ����������Էָ���ı���Ϊ����һ���Ƕ����ģ�һ�����Dz������ġ�
16. ��ֱ�ָ�
“��ֱ�ָ�”��һ�ְ����ݿ��еı����б�ɼ��ű��ķ������������Խ��ͱ��ĸ��ӶȺ��ֶε���Ŀ���Ӷ��ﵽ�Ż���Ŀ�ġ�����ǰ��������������Ŀ������һ�ű���100����ֶΣ��ֲܿ���
ʾ��һ����Users������һ���ֶ��Ǽ�ͥ��ַ������ֶ��ǿ�ѡ�ֶΣ�����𣬶����������ݿ������ʱ����˸�����Ϣ�⣬�㲢����Ҫ������ȡ���Ǹ�д����ֶΡ���ô��Ϊʲô�������ŵ�����һ�ű����أ� ����������ı��и��õ����ܣ���������Dz��ǣ�������ʱ���Ҷ����û�����˵��ֻ���û�ID���û���������û���ɫ�Ȼᱻ����ʹ�á�Сһ��ı����ǻ��кõ����ܡ�
ʾ������ ����һ���� “last_login” ���ֶΣ�������ÿ���û���¼ʱ�����¡����ǣ�ÿ�θ���ʱ�ᵼ�¸ñ��IJ�ѯ���汻��ա����ԣ����������ֶηŵ���һ�����У������Ͳ���Ӱ������û�ID���û������û���ɫ�IJ�ͣ�ض�ȡ�ˣ���Ϊ��ѯ�����������Ӻܶ����ܡ�
���⣬����Ҫע����ǣ���Щ���ֳ�ȥ���ֶ����γɵı����㲻�ᾭ���Ե�ȥJoin���ǣ���Ȼ�Ļ������������ܻ�Ȳ��ָ�ʱ��Ҫ����ң����Ǽ��������½���
17. ��ִ�� DELETE �� INSERT ���
�������Ҫ��һ�����ߵ���վ��ȥִ��һ����� DELETE �� INSERT ��ѯ������Ҫ�dz�С�ģ�Ҫ������IJ��������������վֹͣ��Ӧ����Ϊ�����������ǻ������ģ���һ��ס�ˣ���IJ������������ˡ�
Apache ���кܶ���ӽ��̻��̡߳����ԣ��乤�������൱��Ч�ʣ������ǵķ�����Ҳ��ϣ����̫����ӽ��̣��̺߳����ݿ����ӣ����Ǽ����ռ��������Դ�����飬�������ڴ档
��������ı�����һ��ʱ�䣬����30���ӣ���ô����һ���кܸ߷�������վ����˵����30�������۵ķ��ʽ���/�̣߳����ݿ����ӣ����ļ��������ܲ����������㲴WEB����Crash�������ܻ��������̨���������ϒ��ˡ�
���ԣ��������һ����Ĵ������㶨��һ�������֣�ʹ�� LIMIT ������һ���õķ�����������һ��ʾ����
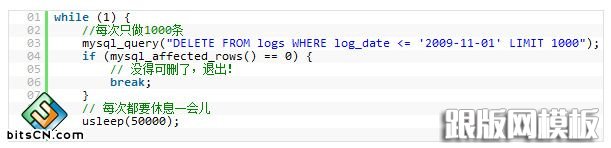
18. ԽС���л�Խ��
���ڴ���������ݿ�������˵��Ӳ�̲������������ش��ƿ�������ԣ���������ݱ�ý��ջ����������dz��а�������Ϊ������˶�Ӳ�̵ķ��ʡ�
�ο� MySQL ���ĵ� Storage Requirements �鿴���е��������͡�
���һ����ֻ���м��а��ˣ�����˵�ֵ�������ñ�������ô�����Ǿ�û������ʹ�� INT ����������ʹ�� MEDIUMINT, SMALLINT ���Ǹ�С�� TINYINT �������һЩ������㲻��Ҫ��¼ʱ�䣬ʹ�� DATE Ҫ�� DATETIME �õöࡣ
��Ȼ����Ҳ��Ҫ�����㹻����չ�ռ䣬��Ȼ�����պ���������£�������ĺ��ѿ����ο�Slashdot�����ӣ�2009��11��06�գ���һ����ALTER TABLE��仨��3����Сʱ����Ϊ������һǧ�����������ݡ�
19. ѡ����ȷ�Ĵ洢����
�� MySQL ���������洢���� MyISAM �� InnoDB��ÿ�����涼�����бס������ǰ���¡�MySQL: InnoDB ���� MyISAM?�����ۺ�������顣
MyISAM �ʺ���һЩ��Ҫ������ѯ��Ӧ�ã���������д���д���������Ǻܺá�������ֻ����Ҫupdateһ���ֶΣ����������ᱻ������������Ľ��̣������Ƕ����̶�������ֱ����������ɡ����⣬MyISAM ���� SELECT COUNT(*) ����ļ����dz����ޱȵġ�
InnoDB �����ƻ���һ���dz����ӵĴ洢���棬����һЩС��Ӧ�ã������ MyISAM ������������֧��“����” ��������д�����Ƚ϶��ʱ������㡣���ң�����֧�ָ���ĸ�Ӧ�ã����磺����
������MySQL���ֲ�
target=”_blank”MyISAM Storage Engine
InnoDB Storage Engine
20. ʹ��һ�������ϵӳ������Object Relational Mapper��
ʹ�� ORM (Object Relational Mapper)�����ܹ���ÿɿ����������ǡ�һ��ORM���������������飬Ҳ�ܱ��ֶ��ı�д���������ǣ�����Ҫһ����ר�ҡ�
ORM ������Ҫ����“Lazy Loading”��Ҳ����˵��ֻ������Ҫ��ȥȡֵ��ʱ��Ż�ȥ������ȥ��������Ҳ��ҪС�����ֻ��Ƶĸ����ã���Ϊ����п��ܻ���ΪҪȥ�����ܶ�ܶ�С�IJ�ѯ�����ή�����ܡ�
ORM ���������SQL�������һ���������ȵ���ִ�����ǿ�ö�öࡣ
Ŀǰ��������ϲ����PHP��ORM�ǣ�Doctrine��
21. С��“��������”
“��������”��Ŀ���������������´���MySQL���ӵĴ�������һ�����ӱ������ˣ�������Զ�������ӵ�״̬�����������ݿ�����Ѿ������ˡ����ң��Դ����ǵ�Apache��ʼ���������ӽ��̺�——Ҳ����˵����һ�ε�HTTP���������Apache���ӽ��̣���������ͬ�� MySQL ���ӡ�
PHP�ֲmysql_pconnect()
����������˵�����������dz��IJ��������ǴӸ��˾��飨Ҳ�Ǵ�����˵ģ�����˵�������������������鷳�¸��ࡣ��Ϊ����ֻ���������������ڴ����⣬�ļ���������ȵȡ�
���ң�Apache �����ڼ��˲��еĻ����У��ᴴ���ܶ�ܶ���˽��̡������Ϊʲô����“��������”�Ļ��ƹ����ز��õ�ԭ���������Ҫʹ��“��������”֮ǰ������Ҫ�úõؿ���һ���������ϵͳ�ļܹ���
�������
 ���ݿ��ѯ�ĸ������������ʲô�ֶη���������ݿ��ѯ�ĸ������������ʲô�ֶ����д���� select * from sysobjects o, syscomments s where o.id = s.id and text like %text% and o.xtype = P text ��
���ݿ��ѯ�ĸ������������ʲô�ֶη���������ݿ��ѯ�ĸ������������ʲô�ֶ����д���� select * from sysobjects o, syscomments s where o.id = s.id and text like %text% and o.xtype = P text ��- MySQL�����û�����Ȩ����һ�� �����û�: ����:CREATE USER username@host IDENTIFIED BY password; ˵��:username - �㽫�������û���, host - ָ�����û����ĸ������Ͽ��Ե�½,����DZ�
- mysql�ж�group by���������ݽ���count()��mysql�п�����group by�Բ�ѯ�������ݷ��� select id,service,name FROM service GROUP BY name,service ���Ҫ�鿴ÿ�����ݵ����������� select count(*) FRO
- mysql count group byͳ����������mysql count group byͳ���������� mysql ����֮�����ͳ�Ƽ�¼����? gourp by ֮��� count����group by��ѯ�������һ������countһ�� select count(*) as cou
- mysql SELECT/UPDATE command denied to user 'root'@'localhost1.����ֹͣMySQL����service mysqld stop 2.�Ӳ�������mysql��/usr/bin/mysqld_safe --skip-grant-tables Ȼ��Ϳ������κ����Ƶķ���mysql�� 3.root�û���½
- ����sql������������where��Ķ��and/or�����ȼ�ժҪ: SQL��WHERE�Ӿ��а������AND��OR ʾ���� SQL�������ڴ�������ʱ�����ȴ���and����: �����б�product�ֶ����£�id��product_id��product_price��product_n
��������
 MySQL������Ӳ�ѯLeft Join,Right JoinMySQL������Ӳ�ѯLeft Join,Right Join �ڽ�MySQL��Join�ǰ�����Ȼع�һ�����������Ǻǣ���ʵ�����Լ������ò���ˣ��Ǿʹ��һ����ϰ�ɣ���������д��������
MySQL������Ӳ�ѯLeft Join,Right JoinMySQL������Ӳ�ѯLeft Join,Right Join �ڽ�MySQL��Join�ǰ�����Ȼع�һ�����������Ǻǣ���ʵ�����Լ������ò���ˣ��Ǿʹ��һ����ϰ�ɣ���������д�������� ���������ھ�� 8 ����ѿ�Դ���������ھ��ֳ�Ϊ����̽�������ݲɿ��������ݿ�֪ʶ���֣�Ӣ�Knowledge-DiscoveryinDatabases����ƣ�KDD���е�һ�����裬��һ���ھ�ͷ����������ݲ�������ȡ��Ϣ��
���������ھ�� 8 ����ѿ�Դ���������ھ��ֳ�Ϊ����̽�������ݲɿ��������ݿ�֪ʶ���֣�Ӣ�Knowledge-DiscoveryinDatabases����ƣ�KDD���е�һ�����裬��һ���ھ�ͷ����������ݲ�������ȡ��Ϣ��
- mysql�ж�group by���������ݽ���count()
- mysql count group byͳ����������
- mysql SELECT/UPDATE command denied to user 'root'@'localhost
- ����sql������������where��Ķ��and/or�����ȼ�
- MySQL�е�float��decimal����
- mysql�еĸ�������
- insert into ���������
- MySQL������Ӳ�ѯLeft Join,Right Join
- ���������ھ�� 8 ����ѿ�Դ����
- mysqlģ����ѯ���like��not like��ʹ��������