重塑存储在集合中并导出到 CSV 的数组
时间:2023-10-02问题描述
我有一个存储在 Mongo 数据库/JSON 文件中的 Facebook 页面赞(标题为 pagelikes)集合.下面是一个条目的示例.
I have a collection of Facebook Page Likes (titled pagelikes) that is stored in a Mongo database/JSON file. Below is an example of one entry.
{
"_id" : ObjectId("4725bf8731b8faf4c04595bb"),
"user_id" : "0939bf9w9804842f9f817ad100",
"page_likes" : [
{
"id" : "859302873383",
"name" : "Hotdogs"
},
{
"id" : "8593683902",
"name" : "Video Games"
},
{
"id" : "849204859849028",
"name" : "Road Bikes"
}
]
}
id = Facebook 页面的唯一标识符,name = Facebook 页面的名称.
id = the unique Facebook Page identifier, name = the name of a Facebook page.
我想将整个集合导出到一个包含三列的 CSV 文件,user_id、page_likes.id、page_likes.name.如下所示:
I would like to export this entire collection to a CSV file with three columns, user_id, page_likes.id, page_likes.name. It would look like the following:
user_id page_likes.id page_likes.name
0939bf9w9804842f9f817ad100 859302873383 Hotdogs
0939bf9w9804842f9f817ad100 8593683902 Video Games
0939bf9w9804842f9f817ad100 849204859849028 Road Bikes
... ... ...
JSON 文件非常大(4GB),包含超过 120K 的用户,并且条目的数量没有限制.
The JSON file is quite large (4GB), contains over 120K users, and there is no limit on the number of an entry has.
我尝试过使用 mongoexport 并失败了,尽管聚合框架似乎最有用(可能是项目和展开功能).也就是说,我对 Mongo 的经验很少.
I have tried and failed with mongoexport, although an aggregation framework seems most useful (possibly the project and unwind functions). That said, I have little experience with Mongo.
任何建议、示例或建议都会非常有帮助.
Any advice, examples or suggestions would be very helpful.
非常感谢,
R
推荐答案
您可以通过多种方式处理此问题.
You can deal with this in a number of ways.
首先,如果您有可用的 MongoDB 3.4,那么您可以使用 "View" 为了用数组内容un-wound"来表示集合.视图"基本上是一个聚合管道语句,就大多数使用集合的操作而言,它似乎是一个普通集合.
Firstly if you have MongoDB 3.4 available then you could use a "View" in order to represent the collection with the array contents "un-wound". A "View" is basically an aggregation pipeline statement that appears to be a normal collection as far as most actions that would use a collection are concerned.
因此假设您的源集合在此处称为 "pages",那么您将使用以下命令创建视图":
So presuming your source collection is called "pages" here, then you would create the "View" with:
db.createView("pageArray", "pages", [{ "$unwind": "$page_likes" }])
然后就可以正常查询集合了:
Then you can query the collection as normal:
db.pageArray.find()
/* 1 */
{
"_id" : ObjectId("4725bf8731b8faf4c04595bb"),
"user_id" : "0939bf9w9804842f9f817ad100",
"page_likes" : {
"id" : "859302873383",
"name" : "Hotdogs"
}
}
/* 2 */
{
"_id" : ObjectId("4725bf8731b8faf4c04595bb"),
"user_id" : "0939bf9w9804842f9f817ad100",
"page_likes" : {
"id" : "8593683902",
"name" : "Video Games"
}
}
/* 3 */
{
"_id" : ObjectId("4725bf8731b8faf4c04595bb"),
"user_id" : "0939bf9w9804842f9f817ad100",
"page_likes" : {
"id" : "849204859849028",
"name" : "Road Bikes"
}
}
随后发出 mongoexport 就好像它是一个普通的集合:
And subsequently issue the mongoexport as if it were a normal collection:
mongoexport -d test -c pageArray --type=csv --fields user_id,page_likes.id,page_likes.name
2017-07-05T13:14:11.588+1000 connected to: localhost
user_id,page_likes.id,page_likes.name
0939bf9w9804842f9f817ad100,859302873383,Hotdogs
0939bf9w9804842f9f817ad100,8593683902,Video Games
0939bf9w9804842f9f817ad100,849204859849028,Road Bikes
2017-07-05T13:14:11.589+1000 exported 3 records
当然要添加 --out 或标准重定向以实际输出到文件.
Of course adding --out or a standard redirect to actually output to a file.
如果您的 MongoDB 是旧版本,但至少有 $out 可用(来自 MongoDB 2.6)然后写入另一个集合:
If your MongoDB is an older version but at least has $out available ( from MongoDB 2.6 ) then write to another collection:
db.pages.aggregate([
{ "$unwind": "$page_likes" },
{ "$project": { "_id": 0 } },
{ "$out": "pagesArray" }
])
然后你基本上运行与上面相同的 mongoexport,因为它也是一个可以访问的集合.
Then you basically run the same mongoexport as above since it's also a collection that is accessible to do so.
如果您真的不想创建视图"或另一个集合",那么您可以简单地向 mongo shell 发送一个简短的脚本.尽管以一种非常老套的方式:
If you really don't want to create either a "View" or "another collection", then you could simply send a short script to the mongo shell. Albeit in a very hacky way:
mongo --quiet --eval '
print("user_id,page_likes.id,page_likes.name");
db.pages.aggregate([
{ "$unwind": "$page_likes" },
{ "$project": { "_id": 0 } },
]).forEach(p => print(`${p.user_id},${p.page_likes.id},${p.page_likes.name}`))'
甚至根本没有 aggregate() 和 $unwind:
Or even without aggregate() and $unwind at all:
mongo --quiet --eval '
print("user_id,page_likes.id,page_likes.name");
db.pages.find({},{ _id: 0 }).forEach(p =>
p.page_likes.forEach(l => print(`${p.user_id},${l.id},${l.name}`)))'
这会为您提供相同的输出:
Which gives you the same output:
user_id,page_likes.id,page_likes.name
0939bf9w9804842f9f817ad100,859302873383,Hotdogs
0939bf9w9804842f9f817ad100,8593683902,Video Games
0939bf9w9804842f9f817ad100,849204859849028,Road Bikes
还请注意,如果您想要或需要"与逗号 , 不同的分隔符,那么最后两种使用 shell 的方法中的任何一种都可能是可行的方法.因为这是计划"添加到 mongoexport 和 mongoimport 与 TOOLS-87,但当然是尚未解决".所以如果你想要不同的输出,那么你自己做吧.
Note also that if you want or "need" a different delimiter than comma ,here, then either of the two last approaches with the shell is probably the way to go. As this is "scheduled" for addition to mongoexport and mongoimport with TOOLS-87, but of course is "yet to be resolved". So if you want different output, then you do it yourself.
这篇关于重塑存储在集合中并导出到 CSV 的数组的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持跟版网!
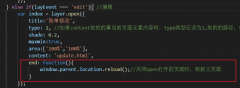 layer.open打开的页面关闭时,父页面刷新的方法layer.open打开的页面关闭时,父页面刷新的方法,在layer.open中添加: end: function(){ window.parent.location.reload();//关闭open打开的页面时,刷新父页面 }
layer.open打开的页面关闭时,父页面刷新的方法layer.open打开的页面关闭时,父页面刷新的方法,在layer.open中添加: end: function(){ window.parent.location.reload();//关闭open打开的页面时,刷新父页面 }