复制站点与DeDecms防采集的方法
时间:2014-11-28去年年底,某客户找我帮忙制作了一个企业网站,考虑到网站日后要进行搜索引擎推广,因此,网站在SEO上必须具备搜索引擎友好性,权衡左右,最终我选择了DeDeCMS,这样可以在URL、PageTitle、TextBlock、LinkBlock、Auto Sitemap、Related Article几方面及早进行SEO布局。于是,在栏目规划、布局设计、模板制作阶段,我便将各种SEO元素充分融入整个制作阶段,期望站点上线后,搜索排名权重可以快速积累。特别是在模板代码撰写方面,有效的控制链接输出与导入,尽可能提高内链接的相关性以及关键词匹配的位置,并去除了无用的网页噪音信息,使每类页面主题都特别突出。
果不其然,网站正式发布后,网站收录比例很快达到70%,绝大多数产品终端页被收录,部分资讯页面被收录,更重要的是:行业关键词排名与产品关键词排名进步飞速;整个网站在SEO运转中呈良性发展趋势。客户开始接手网站并正常更新站点内容,按照设定的计划,一切本应该顺利进展。
然而就在近期,网站SEO表现开始下滑,首当其冲的是网页收录数量,在百度统计后台显示的页面索引量与搜索框中site命令返回结果数差别明显,site命令显示只有2个页面被收录,均是首页,带www与不带www的两个版本的首页。除此之外,当资讯被正常更新后,百度很快索引了,短时间内通过site命令可以返回结果,但时间不长即又发现收录失效。综合上述情况,我认为网站已经被百度降权了。
为了找到问题所在,我研究了各个方面的影响因素,结果发现:
(1)除了正常更新网站内容外,企业方也在积极运作外链,建设外链本来是好事,但却用错了方式,参与了资源站的链轮;
(2)网上惊现模板相同、内容相同、品牌不同的仿制站,而且仿制站在百度收录也是只有首页,与客户网站“惊人的相似”。
1、关于链轮问题,还好我及时发现并制止了这种行为,由于只有几篇产品页参与了链轮,时间不长,应该不至于影响如此之大,何况还是自身资源站点。
2、关于复制站点,已经很少见了,大部分人都会有意识的形成站点内容或者组织形式上的差异化;而客户网站出现这样的SEO症状,恐怕关键就在于仿制站点,当在我看到仿制站的一刻我彻底无语了,除了企业品牌名称不同,网站其他东西我都太清楚了;我很想吐槽,可回头一想现在的互联网不就流行各处抄袭的风气吗,也许习惯了就好,可我TM实在不能忍受的是,模板100%仿制就算了,数据原封不动的采集过去也罢了,拜托,你TMD敢不把99%雷同的站点整体发布出来吗!你TMD搞SEO不知道相似站点啊!你TMD仿站还能把我写的自动更新网站地图文件sitemap.php也能仿制过去!做SEO的伤不起啊。
吐槽归吐槽,问题还是需要解决的,采用了几下的办法:
1、调整模板数据调用规则与新内容块布置
新内容块产生将页面主题关键词更分散一些,同时调整数据调用规则,让仿制站点的数据与自身页面数据产生差异性,降低复制网站SEO问题的负面影响。
2、找到防止内容采集的办法
DeDeCMS自身有防采集混淆字符串的功能,但这种防采集的办法对SEO很不利,你总不想让搜索蜘蛛看到网页中有不少隐藏文本吧,而且这些文本会影响蜘蛛对信息块主题的判断,影响关键词排名,其实,DeDeCMS没有根本性的防采集的方法,道高一尺魔高一丈啊,只要你的信息通过页面的方式发布出来,总能找到采集的方法;综合网上收集的信息,我采纳了两种办法,只能放置最初级的采集:
(1)办法一:复制网页正文内容时自动添加版权信息
JavaScript代码
<script language="javascript" type="text/javascript">
<!--
document.body.oncopy = function() {
setTimeout( function() {
var text = clipboardData.getData("text");
if (text) {
texttext = text + "\r\n(这里是你的文章版权信息,去掉括号):"+location.href;
clipboardData.setData("text", text);
}
}, 100 )
}
-->
</script>
将以上代码放置在文章页模板中正文结束后面即可。我测试了下该方法,只针对IE浏览器有效,而Firefox、遨游、Google Chrome均无效。
(2)办法二:使页面代码具有唯一性
一般别人采集的时候都是要获取内容开始的代码和结束的代码,而且要唯一性的,所以填的开始代码大多是:<div>。这样,我们在这个class后面加上文章的ID值,改成这样<div id="{dede:field.id/}">,这里{dede:field.id/}在dedecms中是获取当前文章的ID值,那么生成的每一篇文章的ID值都不一样,这里的开始代码也就都不一样了,这样别人就采集不到了,采一次只能采一篇。
我们制作模板的时候在在body标记附近的<div>修改成<div>,注意是空格+{dede:field.id/},这样div的class还是没有变,但产生了<div>,这段代码在每篇文章的内文页均是唯一性的,或者在html标记里插入id={dede:field.id/},比如:<div id={dede:field.id/}>与<body id={dede:field.id/}>,这里{dede:field.id/}在dedecms中是获取当前文章的ID值,这样别人就采集不到了,采一次只能采一篇。当然,别人可以使用过滤规则来去掉,但是假如我在所有的class里插入文档ID,或者插入id=文档ID这样的。那他就只能采集整个页面,然后再过滤,使采集变得更加复杂。
缺点:如果插入{dede:field.id/}不够多的话别人可以用过滤规则过滤掉。但是对于一些站群采集软件来说,这一招足以防止他们采集了!
3、升级DeDeCMS至最新版
DeDeCMS旧版有漏洞,很容易被黑,要么就是嵌入各种广告代码,要么就是被无端增加超级多的隐藏链接,所以,务必要升级到最新版。
相关文章
 织梦模板DEDECMS不显示未审核tag标签文档的的方法未审核文档的TAG会显示在TAG列表页面, 固然点击进入TAG时, 相关的未审核文章不会显示出来, 这样对用户体验是很不好的. DEDECMS暂时没有提供这个功能,所以要解
织梦模板DEDECMS不显示未审核tag标签文档的的方法未审核文档的TAG会显示在TAG列表页面, 固然点击进入TAG时, 相关的未审核文章不会显示出来, 这样对用户体验是很不好的. DEDECMS暂时没有提供这个功能,所以要解- 织梦DEDECMS后台文件管理器、模板文件、缩略图排序修改我们都知道DEDECMS生成的文件夹是按天生成的,只要传了图片就会自动建立个年月日的文件,centos系统下,都是随便排序的,很难找到对应文件夹,如果要按顺序排列
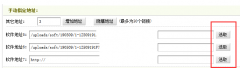 dedecms软件模型手动指定地址增加选取本地文件方法我们在用到织梦dedecms软件模型的时候,手动指定地址通常只能是引用其他网址或者链接,我们要实现直接选取站内的文件,这个要怎么操作呢?下面小编一步步为您解
dedecms软件模型手动指定地址增加选取本地文件方法我们在用到织梦dedecms软件模型的时候,手动指定地址通常只能是引用其他网址或者链接,我们要实现直接选取站内的文件,这个要怎么操作呢?下面小编一步步为您解- dedecms织梦批量修改文章点击量我们有时候需要对织梦文档的点击量进行批量维护,比如采集来的文章,点击量都为0,需要批量修改,可以用到如下方法1。 1、在数据库里运行下面的代码就可以了,文
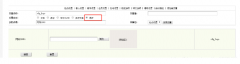 织梦dedecms后台系统基本参数中增加logo上传功能用过dedecms的朋友都知道,织梦cms后台系统基本参数里是无法直接上传图片的,我们更换logo图只能到ftp里替换,非常的不方便,我们如果想直接在系统基本参数里上
织梦dedecms后台系统基本参数中增加logo上传功能用过dedecms的朋友都知道,织梦cms后台系统基本参数里是无法直接上传图片的,我们更换logo图只能到ftp里替换,非常的不方便,我们如果想直接在系统基本参数里上- 织梦dedecms调用所有栏目的子栏目(不包含父栏目)dedecms要想调用所有子栏目是没有这个标签的,要调用只可用sql标签,reid表示子栏目,channeltype=6表示模型为商品,sortrank表示按排序升序.小的放前面 {dede:sql
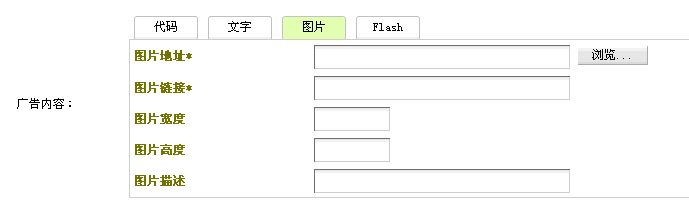 dede5.7织梦后台广告插件增加图片上传功能dede织梦默认的广告插件不错,但是美中不足的是图片部分没法直接上传图片,只能够用ftp上传到程序后再写上地址用。不管是我们自己使用还是给客户做的网站使用都很不方便,
dede5.7织梦后台广告插件增加图片上传功能dede织梦默认的广告插件不错,但是美中不足的是图片部分没法直接上传图片,只能够用ftp上传到程序后再写上地址用。不管是我们自己使用还是给客户做的网站使用都很不方便,