织梦DedeCms采集规则教程
时间:2013-12-25楚截图和文字分不清楚,因此用粉色背景来区分。
第一步、确定采集的网站(我们以DEDE的官方站做为采集站做示范)
第二步、确定被采集站的编码。打开被采集的网页之后,查看源代码(IE:查看 - > 源代码)

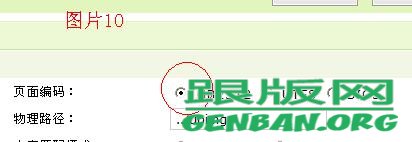
在 之间找到 charset 这个,后面就显示网页的编码了,截图的是 “gb2312”
第三步、采集列表获取规则写法
[var:分页]

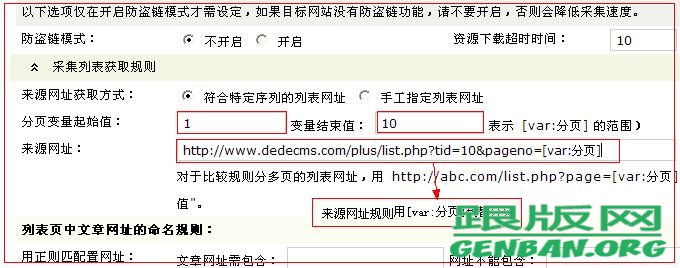
文章网址需包含 网址不能包含 这两个一般不用写,用于采集列表范围有很多不需要的连接才用到他来做过滤使用。
如果只有一个列表页,那么在来源网址就直接写上网址就OK了。


注意这里,最关键就是这里。
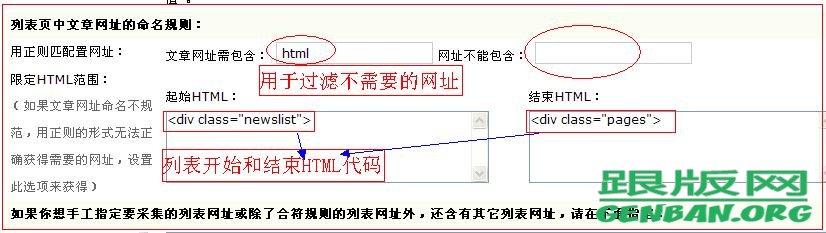
下面就是“采集获取文章列表的规则写法”,
就是上面打开的被采集页面的源代码文件,找到文章列表之前 和本页面没有其他相同的代码
在DedeCms官方站的列表页文章列表之前和之后最近的且没有相同的是“
”和“ ”,分别写入“起始HTML”和“结束HTML”,写法看截图
第四步、采集文章标题,文章内容,文章作者,文章来源等规则写法,分页采集等。
“起始HTML”和“结束HTML”写法参考第三步中的“获取文章列表的规则写法”

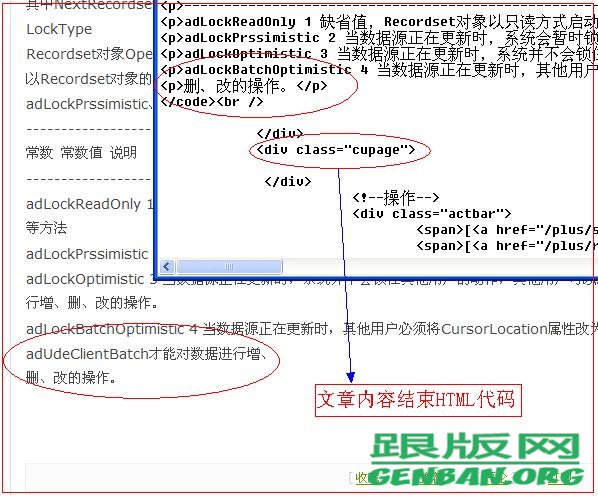
下面讲的是如何采集分页内容 看截图圈着的地方 截图
文档是否分页 里面选择“全部列出的分页列表”
“起始HTML”和“结束HTML”写法参考第三步中的“获取文章列表的规则写法”


当然 上面这些不能用来采集带有视频的,因为已经过滤了,后面的四行是过滤掉视频的。
相关文章
 dedecms教程:关于面包屑导航栏目链接相对路径的修改关于面包屑导航栏目链接相对路径的修改方法 好吧,自己解决了,现在写出来,希望可以帮到有同样问题的人。 找到/include/typelink.class.php 然后找到下面代码,
dedecms教程:关于面包屑导航栏目链接相对路径的修改关于面包屑导航栏目链接相对路径的修改方法 好吧,自己解决了,现在写出来,希望可以帮到有同样问题的人。 找到/include/typelink.class.php 然后找到下面代码,- Dedecms教程:输出织梦全站RSS文件的方法织梦后台默认生成更新RSS文件是按照网站栏目生成告诉用户每个栏目的RSS订阅地址,保存在data目录下,按分类生成很适合栏目或栏目文章较多的dedecms站点,小型CMS
- dedecms教程:调用图片集所有图片有时候,我们在用dedecms建网站的时候,在图片集内容页需要调用当前文章的所有图片出来,这个时候就需要在内容页吧网站里面的所有图片都调用出来了,该怎么做呢
- dedecms教程:获得某篇文章内容的几种方法dedecms获得某篇文章内容的几种方法,在这里给大家总结了以下三种方法: 1. 使用SQL {dede:sql sql=Select body from `dede_addonarticle` where aid=146} [fiel
- 织梦CMS教程:时间日期dedecms标签大全DEDECMS利用strftime()函数格式化时间的所有参数详解,包括年份日期进制、小时格式等,大家收藏吧,呵. 日期时间格式 (利用strftime()函数格式化时间)0 dedecms
- dedecms教程:删除系统自定义变量的方法本文实例讲述了dedecms删除系统自定义变量的方法。分享给大家供大家参考。具体实现方法如下: 一、问题: 之前添加了个联系电话的系统变量,选错了变量类型,结果
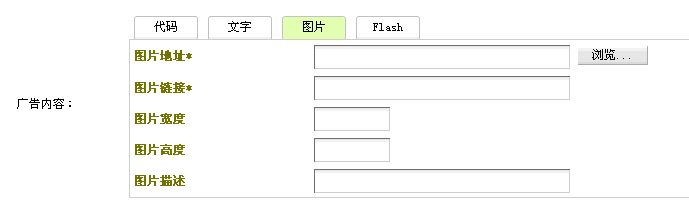 dede5.7织梦后台广告插件增加图片上传功能dede织梦默认的广告插件不错,但是美中不足的是图片部分没法直接上传图片,只能够用ftp上传到程序后再写上地址用。不管是我们自己使用还是给客户做的网站使用都很不方便,
dede5.7织梦后台广告插件增加图片上传功能dede织梦默认的广告插件不错,但是美中不足的是图片部分没法直接上传图片,只能够用ftp上传到程序后再写上地址用。不管是我们自己使用还是给客户做的网站使用都很不方便,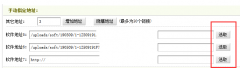 dedecms软件模型手动指定地址增加选取本地文件方法我们在用到织梦dedecms软件模型的时候,手动指定地址通常只能是引用其他网址或者链接,我们要实现直接选取站内的文件,这个要怎么操作呢?下面小编一步步为您解答,最终效
dedecms软件模型手动指定地址增加选取本地文件方法我们在用到织梦dedecms软件模型的时候,手动指定地址通常只能是引用其他网址或者链接,我们要实现直接选取站内的文件,这个要怎么操作呢?下面小编一步步为您解答,最终效