为什么这些 fetch 方法是异步的?
时间:2023-10-02问题描述
Fetch 是新的基于 Promise 的 API,用于发出网络请求:
Fetch is the new Promise-based API for making network requests:
fetch('https://www.everythingisawesome.com/')
.then(response => console.log('status: ', response.status));
这对我来说很有意义 - 当我们发起网络调用时,我们返回一个 Promise,它让我们的线程继续处理其他业务.当响应可用时,Promise 中的代码就会执行.
This makes sense to me - when we initiate a network call, we return a Promise which lets our thread carry on with other business. When the response is available, the code inside the Promise executes.
但是,如果我对响应的负载感兴趣,我会通过响应的方法而不是属性来实现:
However, if I'm interested in the payload of the response, I do so via methods of the response, not properties:
- arrayBuffer()
- blob()
- formData()
- json()
- 文本()
这些方法返回承诺,我不清楚为什么.
These methods return promises, and I'm unclear as to why.
fetch('https://www.everythingisawesome.com/') //IO bound
.then(response => response.json()); //We now have the response, so this operation is CPU bound - isn't it?
.then(entity => console.log(entity.name));
为什么处理响应的负载会返回一个承诺 - 我不清楚为什么它应该是异步操作.
Why would processing the response's payload return a promise - it's unclear to me why it should be an async operation.
推荐答案
为什么这些 fetch 方法是异步的?
Why are these fetch methods asynchronous?
天真的答案是"因为规范是这么说的"
arrayBuffer()方法在调用时必须返回运行使用 ArrayBuffer 使用 body.blob()方法在调用时必须返回运行 使用 Blob 消耗 body.formData()方法在调用时必须返回运行使用 FormData 使用 body.json()方法在调用时必须返回运行使用 JSON 消费正文.text()方法在调用时必须返回运行 使用正文 和文本.
- The
arrayBuffer()method, when invoked, must return the result of running consume body with ArrayBuffer.- The
blob()method, when invoked, must return the result of running consume body with Blob.- The
formData()method, when invoked, must return the result of running consume body with FormData.- The
json()method, when invoked, must return the result of running consume body with JSON.- The
text()method, when invoked, must return the result of running consume body with text.
当然,这并不能真正回答问题,因为它留下了为什么规范这么说?"的问题.
Of course, that doesn't really answer the question because it leaves open the question of "Why does the spec say so?"
这就是它变得复杂的地方,因为我确信其中的推理,但我没有来自官方来源的证据来证明它.我将尽我所能解释理性,但请注意,此处之后的所有内容都应在很大程度上被视为外部意见.
And this is where it gets complicated, because I'm certain of the reasoning, but I have no evidence from an official source to prove it. I'm going to attempt to explain the rational to the best of my understanding, but be aware that everything after here should be treated largely as outside opinion.
当您使用 fetch API 从资源请求数据时,您必须等待资源完成下载才能使用它.这应该是相当明显的.JavaScript 使用异步 API 来处理此行为,因此所涉及的工作不会阻塞其他脚本,而且――更重要的是――UI.
When you request data from a resource using the fetch API, you have to wait for the resource to finish downloading before you can use it. This should be reasonably obvious. JavaScript uses asynchronous APIs to handle this behavior so that the work involved doesn't block other scripts, and—more importantly—the UI.
资源下载完成后,数据可能非常庞大.没有什么可以阻止您请求超过 50MB 的单一 JSON 对象.
When the resource has finished downloading, the data might be enormous. There's nothing that prevents you from requesting a monolithic JSON object that exceeds 50MB.
如果您尝试同步解析 50MB 的 JSON,您认为会发生什么?它会阻止其他脚本,以及—更重要的是—UI.
What do you think would happen if you attempted to parse 50MB of JSON synchronously? It would block other scripts, and—more importantly—the UI.
其他程序员已经解决了如何以高性能方式处理大量数据:Streams.在 JavaScript 中,流是使用异步 API 实现的,因此它们不会阻塞,如果您阅读 consume body 详细信息,很明显流是用来解析数据的:
Other programmers have already solved how to handle large amounts of data in a performant manner: Streams. In JavaScript, streams are implemented using an asynchronous API so that they don't block, and if you read the consume body details, it's clear that streams are being used to parse the data:
如果 body 为非 null,则令 stream 为 body 的流,否则为空的 ReadableStream 对象.
Let stream be body's stream if body is non-null, or an empty ReadableStream object otherwise.
现在,规范肯定有可能定义两种访问数据的方式:一种用于少量数据的同步 API,另一种用于大量数据的异步 API,但这会导致混乱和重复.
Now, it's certainly possible that the spec could have defined two ways of accessing the data: one synchronous API meant for smaller amounts of data, and one asynchronous API for larger amounts of data, but this would lead to confusion and duplication.
除了 你不需要它.任何可以用同步代码表达的东西都可以用异步代码表达.反过来是不正确的.因此,创建了一个可以处理所有用例的异步 API.
Besides Ya Ain't Gonna Need It. Everything that can be expressed using synchronous code can be expressed in asynchronous code. The reverse is not true. Because of this, a single asynchronous API was created that could handle all use cases.
这篇关于为什么这些 fetch 方法是异步的?的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持跟版网!
相关文章
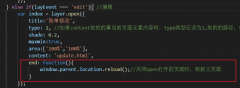 layer.open打开的页面关闭时,父页面刷新的方法layer.open打开的页面关闭时,父页面刷新的方法,在layer.open中添加: end: function(){ window.parent.location.reload();//关闭open打开的页面时,刷新父页面 }
layer.open打开的页面关闭时,父页面刷新的方法layer.open打开的页面关闭时,父页面刷新的方法,在layer.open中添加: end: function(){ window.parent.location.reload();//关闭open打开的页面时,刷新父页面 }- 我可以使用 Fetch 在客户端调用 Twitter API 吗?
- 如何在 React 中执行下一个函数之前完成所有获取?
- TypeError:无法在“窗口"上执行“获取":无效值
- JSON.parse() 与..json()
- 谷歌地图 API;“CORS 标头‘Access-Control-Allow-Origin’缺失"错误
- SCRIPT5009:“获取"未定义
- 如何修复“TypeError:无法获取"?
- Nodejs Parse 获取包含对象 [Symbol(map)] 的响应
- 如何在 fetch/axios 跨站请求中使用 JSONP
- ReactJS“未处理的拒绝(TypeError):this.state.features.map 不是函数"